5th Semester
- M5170 Matematické programování
- Konvexní množiny
- Oddělování konvexních množin
- Konvexní funkce
- Subgradient a subdiferenciál a Fenchelova transformace
- Numerické metody v R
- Numerické metody v R^n
- Nutné a postačující podmínky optimality
- Duální úloha
- Analýza citlivosti
- M5120 Lineární statistické modely
M5170 Matematické programování
Konvexní množiny
$$ \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\norm#1{\left\lVert #1 \right\rVert} \xdef\dist{\rho} \xdef\and{\&}\xdef\brackets#1{\left\{ #1 \right\}} \xdef\parc#1#2{\frac {\partial #1}{\partial #2}} \xdef\mtr#1{\begin{pmatrix}#1\end{pmatrix}} \xdef\bm#1{\boldsymbol{#1}} \xdef\mcal#1{\mathcal{#1}} \xdef\vv#1{\mathbf{#1}}\xdef\vvp#1{\pmb{#1}} \xdef\ve{\varepsilon} \xdef\l{\lambda} \xdef\th{\vartheta} \xdef\a{\alpha} \xdef\tagged#1{(\text{#1})} \xdef\tagged*#1{\text{#1}} \xdef\tagEqHere#1#2{\href{#2\#eq-#1}{(\text{#1})}} \xdef\tagDeHere#1#2{\href{#2\#de-#1}{\text{#1}}} \xdef\tagEq#1{\href{\#eq-#1}{(\text{#1})}} \xdef\tagDe#1{\href{\#de-#1}{\text{#1}}} \xdef\T#1{\htmlId{eq-#1}{#1}} \xdef\D#1{\htmlId{de-#1}{\vv{#1}}} \xdef\conv#1{\mathrm{conv}\, #1} \xdef\cone#1{\mathrm{cone}\, #1} \xdef\aff#1{\mathrm{aff}\, #1} \xdef\lin#1{\mathrm{Lin}\, #1} \xdef\span#1{\mathrm{span}\, #1} \xdef\O{\mathcal O} \xdef\ri#1{\mathrm{ri}\, #1} \xdef\rd#1{\mathrm{r}\partial\, #1} \xdef\interior#1{\mathrm{int}\, #1} \xdef\proj{\Pi} \xdef\epi#1{\mathrm{epi}\, #1} \xdef\grad#1{\mathrm{grad}\, #1} \xdef\hess#1{\nabla^2\, #1} \xdef\subdif#1{\partial #1} \xdef\co#1{\mathrm{co}\, #1} \xdef\iter#1{^{[#1]}} $$
Definice $\D{1.1}$ (Konvexní množina)
Nechť $X \subseteq \R^n$. Množina $X$ se nazývá konvexní, jestliže pro všechna $x_1, x_2 \in X$ a pro každé $\l \in [0,1]$ platí $$ \l x_1 + (1 - \l) x_2 \in X \tag{KM} $$
Speciálně prázdnou množinu $\emptyset$ považujeme za konvexní
Operace nad konvexními množinami
Mějme $X_i, i \in I$ konvexní množiny. Potom
- jejich sjednocení $\bigcap_{i \in I} X_i$ je konvexní množina
- jejich součet $\a_1 X_1 + \dots + \a_m X_m = \brackets{x \in \R^n \mid x = \displaystyle \sum_{i = 1}^m \a_i x_i \text{ pro nějaká } x_i \in X_i}$ je opět konvexní
Vlastnosti konvexních množin
Definice $\D{2.1.3}$ (Speciální množiny)
Množina $X \subseteq \R^n$ se nazývá
-
kužel, jestliže pro každé $x \in X$ a pro každé $\l \in [0, \infty)$ je také $\l x \in X$
-
konvexní kužel, jestliže je množina $X$ konvexní a současně kuželem
-
afinní, jestliže pro každé $x_1, x_2 \in X$ a pro každé $\l \in \R$ platí $$ \l x_1 + (1 - \l)x_2 \in X $$

Polyedr je mnohostěn v $\R^n$. Dále ohraničený polyedr nazveme polytop.
Dále si rozeberme různé kombinace bodů
Definice $\D{2.1.4}$ (Lineární kombinace)
Nechť $x_1, \dots, x_m \in \R^n$. Lineární kombinace $\l_1 x_1 + \dots + \l_m x_m$ se nazývá
- konvexní, jestliže $\l_1, \dots, \l_m \geq 0$ a $\sum_{i = 1}^m \l_i = 1$
- nezáporná, jestliže $\l_1, \dots, \l_m \geq 0$
- afinní, jestliže $\sum_{i = 1}^m \l_i = 1$.
Tedy jistě platí
- Množina obsahující všechny linearní kombinace libovolných dvou svých bodů (tj. s libovolnými dvěma body obsahuje i přímku procházející těmito body a počátek) je vektorový (lineární) prostor
- Množina obsahující všechny afinní kombinace libovolných dvou svých bodů (tj. s libovolnými dvěma body obsahuje i přímku procházející těmito body) je afinní
- Množina obsahující všechny nezáporné kombinace libovolných dvou svých bodů (tj. s libovolnými dvěma body obsahuje i celou výšeč určenou polopřímkami vycházejícími z počátku a procházejícími těmito body) je konvexní kužel
- Množina obsahující všechny konvexní kombinace dvou libovolných svých bodů (tj. s libovolnámi dvěma body obsahuje i celou úsečku je spojující) je konvexní
Definice $\D{2.1.6}$ (Obaly)
Nechť $X \subseteq \R^n$
- průnik všech konvexních množin obsahujících množinu $X$ se nazývá konvexní obal množiny $X$ a značí se $\conv X$.
- průnik všech konvexních kuželů obsahujících množinu $X$ se nazývá kónický obal množiny $X$ a značí se $\cone X$.
- průnik všech afinních množin obsahujících množin $X$ se nazyvá afinní obal množiny $X$ a značí se $\aff X$. Jeho zaměření se nazývá lineární obal množiny $X$ a značí se $\lin X$. Dimenze afinního obalu množiny $X$ se značí $\dim X$ a klademe $\dim X := \dim {\lin X}$.
Všimněme si, že $\span X = \{$ $\forall$ lineární kombinace prvků z $X$ $\}$,
ale $\lin X = \span \brackets{x_2 - x_1, x_3 - x_1, \dots, x_m - x_1}$. (pro $X = \set{x_1, \dots, x_m}$) Viz obrázek z přednášky
Jinak řečeno, konvexní obal je nejmenší konvexní množina obsahující $X$ ve smyslu množinové inkluze.
Kónický obal je nejmenší konvexní kužel obsahující $X$ atd..
Jako simplex definujeme konvexní obal $n+1$ afinně nezávislých bodů $v_1, \dots, v_{n+1} \in \R^m$, kde $m \geq n$. Pod pojmem afinně nezávislé body rozumíme, že vektory $$ v_2 - v_1, v_3 - v_1, \dots, v_{n+1} - v_1 $$ jsou lineárně nezávislé.
Věta $\D{2.1.7}$
Nechť $X \subseteq \R^n$. Pak platí
- $\conv X = \brackets{x \mid x = \displaystyle\sum_{i = 1}^m \l_i x_i, \text{ kde } m \in \N \text{ je libovolné}, x_1, \dots, x_m \in X, \l_1, \dots, \l_m \geq 0, \sum_{i = 1}^m \l_i = 1}$
- $\cone X = \brackets{x \mid x = \displaystyle\sum_{i = 1}^m \l_i x_i, \text{ kde } m \in \N \text{ je libovolné}, x_1, \dots, x_m \in X, \l_1, \dots, \l_m \geq 0}$
- $\aff X = \brackets{x \mid x = \displaystyle\sum_{i = 1}^m \l_i x_i, \text{ kde } m \in \N \text{ je libovolné}, x_1, \dots, x_m \in X, \l_1, \dots, \l_m \in \R, \sum_{i = 1}^m \l_i = 1}$
Libovolný bod x v konvexní kuželu v $\R^n$ lze vyjádřit pomocí nezáporné kombinace $n$ bodů
Věta $\D{2.1.9}$ (Caratheódoryho)
Nechť $X \subseteq \R^n$. Každý bod konvexního obalu $\conv X$ může být vyjádřen jako konvexní kombinace nejvýše $n+1$ prvků množiny $X$, tj. pro $x \in X$ existují $x_1, \dots, x_{n+1} \in X$ a $\l_1, \dots, \l_{n+1} \geq 0$ splňující $\sum_{i = 1}^{n+1} \l_i = 1$ taková, že $$ x = \l_1 x_1 + \dots + \l_{n+1} x_{n+1} $$
POZOR: Univerzální konvexní báze (stejná pro všechny $x \in \conv X$) konvexního obalu $\conv X$ nemusí existovat!
Lze ukázat, že pokud $X \subseteq \R^n$ je kompaktní množina, pak $\conv X$ je také kompaktní.
To stejné neplatí o uzavřenosti.
Zobecnění vnitřku množiny
Definice $\D{2.1.11}$ (Relativně vnitřní bod)
Nechť $X \subseteq \R^n$. Bod $x^* \in X$ se nazývá relativně vnitřním bodem množiny $X$, jestliže existuje okolí $\O(x^* )$ bodu $x^* $ takové, že
$$
\O(x^* ) \cap \aff X \subseteq X
$$
Množinu všech relativně vnitřních bodů nazýváme relativním vnitřkem množiny $X$ a značime $\ri X$.
Množina $\rd X := \overline X \setminus \ri X$ se nazývá relativní hranice množiny $X$.
Jistě platí $\interior X \subseteq \ri X$
a také $\ri X \subseteq X \subseteq \overline X \subseteq \aff X$
Platí $\overline {\ri X} = \bar X$, tj. relativní vnitřek je dost velký na vygenerování uzávěru.
Oddělování konvexních množin
$$ \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\norm#1{\left\lVert #1 \right\rVert} \xdef\dist{\rho} \xdef\and{\&}\xdef\brackets#1{\left\{ #1 \right\}} \xdef\parc#1#2{\frac {\partial #1}{\partial #2}} \xdef\mtr#1{\begin{pmatrix}#1\end{pmatrix}} \xdef\bm#1{\boldsymbol{#1}} \xdef\mcal#1{\mathcal{#1}} \xdef\vv#1{\mathbf{#1}}\xdef\vvp#1{\pmb{#1}} \xdef\ve{\varepsilon} \xdef\l{\lambda} \xdef\th{\vartheta} \xdef\a{\alpha} \xdef\vf{\varphi} \xdef\Tagged#1{(\text{#1})} \xdef\tagged*#1{\text{#1}} \xdef\tagEqHere#1#2{\href{#2\#eq-#1}{(\text{#1})}} \xdef\tagDeHere#1#2{\href{#2\#de-#1}{\text{#1}}} \xdef\tagEq#1{\href{\#eq-#1}{(\text{#1})}} \xdef\tagDe#1{\href{\#de-#1}{\text{#1}}} \xdef\T#1{\htmlId{eq-#1}{#1}} \xdef\D#1{\htmlId{de-#1}{\vv{#1}}} \xdef\conv#1{\mathrm{conv}\, #1} \xdef\cone#1{\mathrm{cone}\, #1} \xdef\aff#1{\mathrm{aff}\, #1} \xdef\lin#1{\mathrm{Lin}\, #1} \xdef\span#1{\mathrm{span}\, #1} \xdef\O{\mathcal O} \xdef\ri#1{\mathrm{ri}\, #1} \xdef\rd#1{\mathrm{r}\partial\, #1} \xdef\interior#1{\mathrm{int}\, #1} \xdef\proj{\Pi} \xdef\epi#1{\mathrm{epi}\, #1} \xdef\grad#1{\mathrm{grad}\, #1} \xdef\gradT#1{\mathrm{grad}^T #1} \xdef\gradx#1{\mathrm{grad}_x #1} \xdef\hess#1{\nabla^2\, #1} \xdef\hessx#1{\nabla^2_x #1} \xdef\jacobx#1{D_x #1} \xdef\jacob#1{D #1} \xdef\subdif#1{\partial #1} \xdef\co#1{\mathrm{co}\, #1} \xdef\iter#1{^{[#1]}} \xdef\str{^*} \xdef\spv{\mcal V} \xdef\civ{\mcal U} \xdef\knvxProg{\tagEqHere{4.1}{./nutne-a-postacujici-podminky-optimality} \, \and \, \tagEqHere{4.2}{nutne-a-postacujici-podminky-optimality}} $$
Oddělitelnost množin
Definice $\D{2.3.1}$ (Oddělitelnost množin)
Neprázdné množiny $X_1, X_2$ se nazývají
-
oddělitelné, jestliže existuje $p \in \R^n \setminus \brackets{\vv 0}$ takové, že
$$\scal p {x_1} \geq \scal p {x_2}$$ pro každé $x_1 \in X_1, x_2 \in X_2$. -
vlastně oddělitelné, jestliže jsou oddělitelné a zároveň existují body $x_1^* \in X_1, x_2^* \in X_2$ takové, že
$$\scal p {x_1^* } > \scal p {x_2^* }$$ -
silně oddělitelné, jestliže existuje $p \in \R^n \setminus \brackets{\vv 0}$ takové, že
$$\inf_{x_1 \in x_1} \scal p {x_1} > \sup_{x_2 \in X_2} \scal p {x_2},$$ je-li navíc $\beta \in [\sup_{x_2 \in X_2} \scal p {x_2}, \inf_{x_1 \in X_1} \scal p {x_1}]$, nadrovina $$H_{p,\beta} := \brackets{x \in \R^n \mid \scal p x = \beta}$$ se nazývá oddělující nadrovinou množin $X_1$ a $X_2$.
Ve vyjádření $\brackets{x \in \R^n \mid \scal p x = \beta}$ značí $p$ normálový vektor nadroviny a $\beta$ její posunutí

Definice $\D{2.3.2}$ (Projekce bodu)
Nechť $X \subseteq \R^n$ je neprázdná množina a $x \in \R^n$. Bod $x^* \in X$ nazveme projekcí bodu $x$ na množinu $X$ a označíme $\proj_X (x)$, jestliže $$ \norm{\proj_X (x) - x} \leq \norm{y - x} $$ pro každé $y \in X$.
Věta $\D{2.3.4}$
Neprázdné konvexní množiny $X_1,X_2 \in \R^n$ jsou silně oddělitelné právě tehdy, když mají nenulovou vzdálenost, tj. $$ \dist (X_1, X_2) := \inf_{x_1 \in X_1, x_2 \in X_2} \norm{x_1 - x_2} > 0, $$ což je ekvivalentní s podmínkou $0 \notin \overline{X_1 - X_2}$.
Pod kompaktní množinou myslíme množinu, která je ohraničená (má konečný průměr) a uzavřená (obsahuje svou hranici).
Pokud jsou množiny $X_1, X_2 \subseteq \R^n$ neprázdné, konvexní a disjunktní a navíc BÚNO je $X_1$ uzavřená a $X_2$ kompaktní, tak jsou množiny silně oddělitelné.
Požadavek kompaktnosti množiny $X_2$ vynechat nelze, viz protipříklad dvou hyperbol (obrázek je pouze ilustrativní)

Věta $\D{2.3.5a}$ (Geometrický popis konvexních množin)
Libovolná uzavřená konvexní množina $X \subseteq \R^n$ je řešením (nekonečné) soustavy neostrých lineárních rovnic.
Geometricky: každá uzavřená konvexní množina $X \subsetneqq \R^n$ je průnikem uzavřených poloprostorů, konkrétně všech uzavřených poloprostorů obsahujících $X$
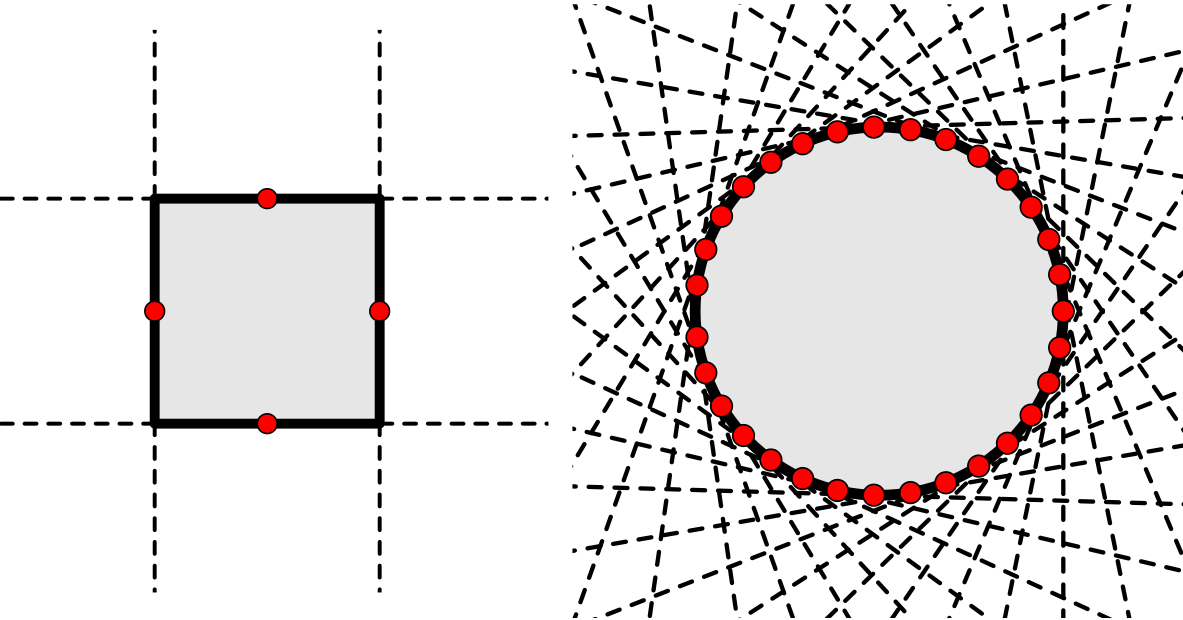
Opěrné nadroviny
Definice $\D{2.3.6}$ (Opěrná nadrovina)
Nechť $X \subseteq \R^n$ je neprázdná množina a nechť $a \in \partial X := \overline X \setminus \interior X$. Nadrovina $H_{p, \beta}$ se nazývá
-
opěrnou nadrovinou množiny $X$ v bodě $a$, jestliže
$$\scal p x \geq \beta = \scal p a$$ pro každé $x \in X$ -
vlastní opěrnou nadrovinou množiny $X$, jestliže je opěrnou nadrovinou množiny $X$ a zároveň existuje $x^* \in X$ takové, že
$$\scal p {x^* } > \beta$$
Jinak řečeno množina musí ležet pouze v jednom z poloprostorů určených opěrnou nadrovinou.
Věta $\D{2.3.7}$ (Existenci opěrné nadroviny)
Nechť $X \subseteq \R^n$ je neprázdná konvexní množina a nechť $a \in \rd X \subseteq \partial X$. Pak v bodě $a$ existuje vlastní opěrná nadrovina množiny $X$.
Pro relativní vnitřek $\ri X$ množiny $X$ a její vnitřek platí $\interior X \subseteq \ri X$ a tedy jistě
$$\overline X \setminus \ri X = \rd X \subseteq \partial X = \overline X \setminus \interior X$$
Podmínky oddělitelnosti
Věta $\D{2.3.7a}$ (Oddělitelnost množin)
Nechť $X_1, X_2 \subseteq \R^n$ jsou neprázdné, konvexní a disjunktní množiny. Pak pro tyto množiny existuje oddělující nadrovina.
Věta $\D{2.3.8}$
Neprázdné konvexní množiny $X_1, X_2 \subseteq \R^n$ jsou vlastně oddělitelné právě tehdy, když $\ri X_1 \cap \ri X_2 = \emptyset$.
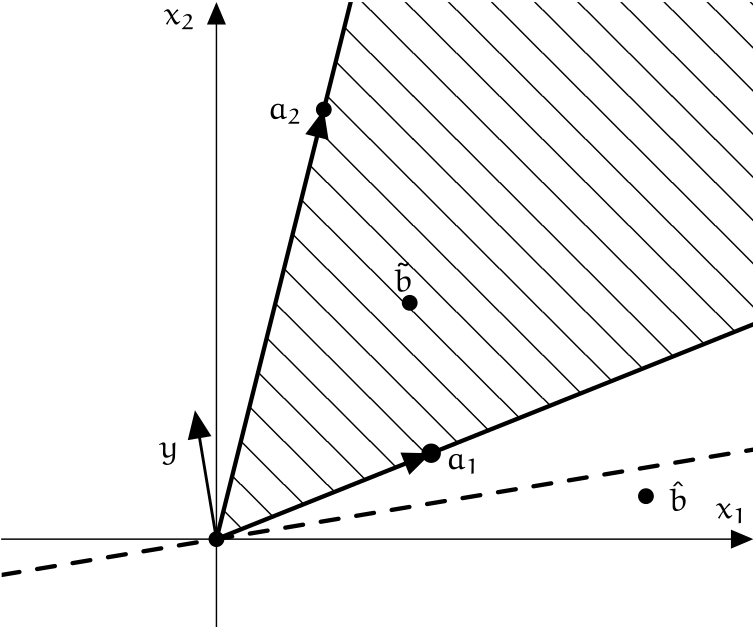
Věta $\D{2.3.9}$ (Farkas & Minkowski)
Nechť $A \in \R^{m \times n}$ a $b \in \R^m$. Potom je právě jeden z následujících systémů rovnic a nerovnic řešitelný: $$ Ax = b, \quad x \geq 0, \tag{\T{2.3.5}} $$ $$ A^T y \geq 0, \quad \scal y b < 0 \tag{\T{2.3.6}} $$
Jinak řečeno soustava $\tagEq{2.3.5}$ má řešení právě tehdy, když pro všechna $y \in \R^m$ platí $A^T y \geq 0$ a zároveň $\scal y b \geq 0$
Ještě jinak můžeme větu formulovat tak, že buď $b$ leží v konvexním kuželu $\cone{\brackets{a_i}_{i=1}^n}$ nebo jsou $b$ a konvexní kužel silně oddělitelné.
Z této věty pak plynou tzv. věty o alternativě, které můžeme najít například v lineárním programování.
Tvrzení Věty $\tagDe{2.3.9}$ můžeme také napsat jako:
Jestliže systém
$$
f_0(x) := \scal {a_0} x < 0, \quad f_i(x) := \scal {a_i} x \leq 0, \quad i \in \brackets{1, \dots, m}
$$
nemá pro daná $a_0, \dots, a_m \in \R^m$ řešení na $\R^n$, pak existují čísla $y_1, \dots, y_m \geq 0$ taková, že
$$
a_0 + \sum_{i = 1}^m y_i a_i = 0, \quad \text{tj. }f_0(x) + \sum_{i = 1}^m y_i f_i(x)= 0
$$
pro každé $x \in \R^n$.
Toto plyne z toho, že pokud v $\tagDe{2.3.9}$ položíme $b = a_0$ a $A = -(a_1, \dots, a_m)$ (a zaměníme-li $x$ a $y$), pak podle předpokladu nemá systém $A^T x \geq 0 \, \and \, \scal x {a_0} < 0$ řešení. A tedy dostáváme, že systém $Ay = a_0, y \geq 0$ řešení mít musí.
Věta $\D{2.3.12}$ (Fan & Glicksburg & Hoffman)
Nechť množina $X \subseteq \R^n$ je konvexní, funkce $f_1, \dots, f_k: X \to \R$ jsou konvexní a funkce $f_{k+1}, \dots, f_m$ afinní, tj. pro $j \in \brackets{k+1, \dots, m}$ máme $f_j = \scal {a_j} x + \beta_j$ pro vhodná $a_j \in \R^n$ a $\beta_j \in \R$. Jestliže systém nerovností a rovností $$ \begin{rcases} f_i(x) < 0, & i \in \brackets{1, \dots, k} \ f_j(x) = 0, & j \in \brackets{k+ 1, \dots, m} \end{rcases} \tag{\T{2.3.8}} $$ nemá řešení na $X$, pak existují takové konstanty $$ y_1, \dots, y_k \geq 0 \quad \and \quad y_{k+1}, \dots, y_m \in \R $$ že pro alespoň jedno $l \in \brackets{1, \dots, m}$ je $y_l \neq 0$ a pro všechna $x \in X$ platí $$ \sum_{i = 1}^m y_i f_i(x) \geq 0 \tag{\T{2.3.9}} $$
Následující věta udává podmínky, které zajišťují kladnost jistého význačného $y_i$ (BÚNO $i = 0$) ve vztahu $\tagEq{2.3.9}$. Po vydělení vztahu $\tagEq{2.3.9}$ tímto $y_i$ dostaneme BÚNO $y_i = 1$.
Věta $\D{2.3.13}$ (Podmínky regularity)
Nechť množina $X \subseteq \R^n$ je konvexní a funkce $f_0, \dots, f_m: X \to \R$ jsou konvexní. Jestliže systém nerovností $$ f_0(x) < 0, \tag{\T{2.3.10}} $$ $$ f_i(x) < 0, \quad i \in \brackets{1, \dots, m} \tag{\T{2.3.11}} $$ nemá řešení na $X$ a podsystém $\tagEq{2.3.11}$ má řešení na $X$, pak existují $y_1, \dots, y_m \geq 0$ taková, že pro všechna $x \in X$ platí $$ f_0(x) + \sum_{i = 1}^m y_i f_i(x) \geq 0 \tag{\T{2.3.12}} $$
Konvexní funkce
$$ \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\norm#1{\left\lVert #1 \right\rVert} \xdef\dist{\rho} \xdef\and{\&}\xdef\brackets#1{\left\{ #1 \right\}} \xdef\parc#1#2{\frac {\partial #1}{\partial #2}} \xdef\mtr#1{\begin{pmatrix}#1\end{pmatrix}} \xdef\bm#1{\boldsymbol{#1}} \xdef\mcal#1{\mathcal{#1}} \xdef\vv#1{\mathbf{#1}}\xdef\vvp#1{\pmb{#1}} \xdef\ve{\varepsilon} \xdef\l{\lambda} \xdef\th{\vartheta} \xdef\a{\alpha} \xdef\tagged#1{(\text{#1})} \xdef\tagEq#1{\href{\#eq-#1}{(\text{#1})}} \xdef\tagDe#1{\href{\#de-#1}{\text{#1}}} \xdef\T#1{\htmlId{eq-#1}{#1}} \xdef\D#1{\htmlId{de-#1}{\vv{#1}}} \xdef\conv#1{\mathrm{conv}\, #1} \xdef\cone#1{\mathrm{cone}\, #1} \xdef\aff#1{\mathrm{aff}\, #1} \xdef\lin#1{\mathrm{Lin}\, #1} \xdef\span#1{\mathrm{span}\, #1} \xdef\O{\mathcal O} \xdef\ri#1{\mathrm{ri}\, #1} \xdef\rd#1{\mathrm{r}\partial\, #1} \xdef\interior#1{\mathrm{int}\, #1} \xdef\proj{\Pi} \xdef\epi#1{\mathrm{epi}\, #1} \xdef\grad#1{\mathrm{grad}\, #1} \xdef\hess#1{\nabla^2\, #1} $$
Definice $\D{2.2.1}$ (Konvexní funkce)
Nechť $X \subseteq \R^n$ je konvexní množina. Funkce $f: X \to \R$ se nazývá
-
konvexní na $X$, jestliže pro všechna $x_1, x_2 \in X$ a každé $\l \in [0,1]$ platí
$$f(\l x_1 + (1 - \l)x_2) \leq \l f(x_1) + (1-\l) f(x_2) \tag{\T{2.2.1}}$$ - ostře konvexní na $X$, jestliže nerovnost $\tagEq{2.2.1}$ je ostrá pro všechna $x_1, x_2 \in X, x_1 \neq x_2$ a každé $\l \in (0,1)$.
-
silně konvexní na $X$ s konstantou silné konvexnosti $\th > 0$, jestliže pro všechna $x_1, x_2 \in X$ a každé $\l \in [0,1]$ platí
$$\underbrace{f(\l x_1 + (1 - \l)x_2) \leq \l f(x_1) + (1 - \l) f(x_2)}_{\tagEq{2.2.1}} - \th \l(1-\l)\norm{x_1 - x_2}^2 \tag{\T{2.2.2}}$$
V praxi je silná konvexnost "silnější" než ostrá konvexnost a ta je silnější než "obyčejná" konvexnost
Věta $\D{2.2.2}$ (Konvexnost nadgrafu)
Nechť $X \subseteq \R^n$ je konvexní množina a nechť $f : X \to \R$. Funkce $f$ je konvexní na $X$ právě tehdy, když její nadgraf (epigraf) $$ \epi f := \brackets{\underbrace{[x, \beta]}_{\text{bod}} \in \R^{n+1} \mid x \in X, \beta \geq f(x)} $$ je konvexní množina.
Pro ostře konvexní funkci musí "tyto dva body" vždy ležet nad sebou (myšleny jejich souřadnice na ose $y$). Navíc pro silnou konvexnost mezi nimi musí vždy být alespoň daná mezera.

Tyto body nemusí ležet nad sebou (na svislé přímce). Navíc ještě
$f$ konvexní $\iff$ $-f$ konkávní
Kombinace konvexních funkcí
Věta $\D{2.2.3}$ (Nezáporná linearní kombinace konvexních funkcí)
Nechť $X \subseteq \R^n$ je konvexní množina, funkce $f_1, \dots, f_m: X \to \R$ jsou konvexní na $X$ a $\a_1, \dots, \a_m \geq 0$ jsou daná čísla. Potom $F(x) = \a_1 f_1(x) + \dots + \a_m f_m(x)$ je konvexní.
Věta $\D{2.2.4}$ (Sublevel set)
Nechť $X \subseteq \R^n$ je konvexní množina a $f: X \to \R$ je konvexní funkce na $X$. Pak pro libovolné $K \in \R$ je odpovídající dolní vrstevnicová množina (sublevel set) $$ V_K := \brackets{x \in X \mid f(x) \leq K} $$ také konvexní.
Platí pouze tato implikace: $f$ konvexní $\implies$ sublevel set konvexní
Například $x^3$ má konvexní sublevel set, ale sama konvexní není.
Přesněji říkáme, že pokud má funkce $f$ konvexní sublevel set, pak $f$ je kvazikonvexní.
Věta $\D{2.2.5}$ (Jensen)
Nechť $X \subseteq \R^n$ je konvexní množina a funkce $f:X \to \R$ je konvexní na $X$. Pak pro libovolné $m \in \N, x_1, \dots, x_m \in X$ a čísla $\l_1, \dots, \l_m \geq 0$ splňující $\sum_{i = 1}^m \l_i = 1$ platí $$ f \left( \sum_{i = 1}^m \l_i x_i \right) \leq \sum_{i = 1}^m \l_i f(x_i). \tag{\T{2.2.3}} $$ Je-li navíc funkce $f$ ostře konvexní a $\l_1, \dots, \l_m \in (0,1)$, pak rovnost v $\tagEq{2.2.3}$ nastane právě tehdy, když $x_1 = \dots = x_m$.
První část Věty $\tagDe{2.2.5}$ lze jistě podle Definice $\tagDe{2.2.1}$ nahradit ekvivalencí
Z Jensenovy nerovnosti $\tagEq{2.2.3}$ lze odvodit například AG nerovnost
$${x_1 + \dots + x_m \over m} \leq \sqrt[m]{x_1 \cdot \ldots \cdot x_m}$$
Lokalizace minima konvexní funkce
Věta $\D{2.2.6}$
Nechť $X \subseteq \R^n$ je konvexní množina a funkce $f: X \to \R$ konvexní. Potom následující tvrzení jsou pravdivá
- Libovolné lokální minimum funkce $f$ na $X$ je současně globálním minimem.
- Množina bodů množiny $X$, v nichž funkce $f$ nabývá svého minima na $X$, je konvexní. Je-li funkce dokonce ostře konvexní, pak je tato množina nejvýše jednoprvková.
- Je-li funkce $f$ diferencovatelná na otevřené množině $\mcal U \supseteq X$ a $x^* \in X$ je jejím stacionárním bodem, tj. $\grad f(x^* ) = 0$, pak $x^* $ je bodem globálního minima funkce $f$ na množině $X$.
Z Věty $\tagDe{2.2.6}$ mimo jiné plyne, že je-li $f: X \to \R$ (ostře) konvexní a spojitá funkce na konvexní a kompaktní množině $X \subseteq \R^n$, pak $f$ má na $X$ (právě jedno) globální minumum.
Věta $\D{2.2.7}$ (Základní věta konvexního programování)
Máme-li konvexní funkci $f: X \to \R$ na polytopu $X := \conv \brackets{x_1, \dots, x_m} \subseteq \R^n$, pak je maximum funkce $f$ na $X$ dosaženo v některém z bodů $x_1, \dots, x_m$.
Obecněji: je-li $X$ konvexní a kompaktní množina, pak maximum nastává v extrémním bodě (tj. v takovém bodě, který není netriviální konvexní kombinací dvou bodů z $X$)
Z Věty $\tagDe{2.2.7}$ plyne základní věta lineárního programování:
Je-li funkce $f$ afinní (taková funkce je konvexní i konkávní zároveň), pak globální maximum nastává v některém z bodů $x_1, \dots, x_m$, tj. v některém z "vrcholů" polytopu.
Vlastnosti konvexních funkcí
Věta $\D{2.4.1}$ (Spojitost konvexní funkce)
Nechť $X \subseteq \R^n$ je konvexní množina a funkce $f: X \to \R$ je konvexní na $X$. Pak $f$ je spojitá pro každé $x \in \ri X$.
Dále ještě známe několik podmínek zaručujících konvexnost funkce $f: \R \to \R$:
- má-li $f$ vlastní derivaci v otevřeném intervalu $I$, pak $f$ je (ostře) konvexní na $I$ právě tehdy, když $f'$ je neklesající (rostoucí) na $I$.
- má-li $f$ vlastní derivaci v otevřeném intervalu $I$, pak $f$ je (ostře) konvexní na $I$ právě tehdy, když pro každé $x, x^* \in I$ platí
$$f(x) \geq^{(>)} f(x^* ) + f'(x^* )(x - x^* ),$$ tj. graf funkce $f$ leží nad tečnou sestrojenou v libovolném bodě. - má-li $f$ vlastní druhou derivaci v otevřeném intervalu $I$, pak $f$ je konvexní na $I$ právě tehdy, když funkce $f''(x) \geq 0$ (je-li $f''(x) > 0$ na $I$, pak ostře konvexní)
Tyto tvrzení si nyní rozšiřme pro $f: \R^n \to \R$ pro silnou konvexnost s konstatnou $\th$ (volbou $\th = 0$ dostáváme ostrou konvexnost)
Věta $\D{2.4.2}$
Nechť $X \subseteq \R^n$ je konvexní množina a funkce $f$ diferencovatelná na otevřené množině $\mcal U \supseteq X$. Pak $f$ je silně konvexní na $X$ s konstantou silné konvexnosti $\th \geq 0$ právě tehdy, když pro každé $x, x^* \in X$ platí $$ f(x) \geq f(x^* ) + \scal {\grad f(x^* )} {x - x^* } + \th \norm{x - x^* }^2 \tag{\T{2.4.1}} $$
Ve $\tagEq{2.4.1}$ výraz $\scal {\grad f(x^* )} {x - x^* }$ hraje úlohu tečné nadroviny v bodě $x^* $ s normálovým vektorem $\grad f(x^* )$ (tečným jak na nadrovinu, tak na funkci $f$ v bodě $x^* $)
Ještě jinými slovy je z Věty $\tagDe{2.4.2}$ plyne, že nadrovina daná $\scal {\grad f(x) - \grad f(x^* )} {x - x^* } \geq \th \norm{x - x^* }^2$ opěrnou nadrovinou pro $\epi f$
Důsledek $\D{2.4.5}$
Nechť $X \subseteq \R^n$ je konvexní množina splňující $\interior X \neq \emptyset$. Nechť funkce $f: X \to \R$ je dvakrát spojitě diferencovatelná na otevřené množině $\mcal U \supseteq X$ s maticí druhých derivací $\hess f(x)$ (Hessova matice). Pak $f$ je silně konvexní na $X$ s konstantou silné konvexnosti $\th \geq 0$ právě tehdy, když pro každé $x \in X$ a $h \in \R^n$ platí $$ \scal {\hess f(x)} h \geq 2 \th \norm{h}^2 \tag{\T{2.4.3}}, $$ jinými slovy $\hess f(x) \geq 2 \th I$ pro všechna $x \in X$.
Z Důsledku $\tagDe{2.4.5}$ plynou následující tři implikace
- $\hess f(x) \geq 0$ pro všechna $x \in X \implies f$ je konvexní na $X$
- $\hess f(x) > 0$ pro všechna $x \in X \implies f$ je ostře konvexní na $X$
- $\interior X \neq \emptyset$ a $f$ je konvexní na $X \implies \hess f(x) \geq 0$ pro všechna $x \in X$
Subgradient a subdiferenciál a Fenchelova transformace
$$ \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\norm#1{\left\lVert #1 \right\rVert} \xdef\dist{\rho} \xdef\and{\&}\xdef\brackets#1{\left\{ #1 \right\}} \xdef\parc#1#2{\frac {\partial #1}{\partial #2}} \xdef\mtr#1{\begin{pmatrix}#1\end{pmatrix}} \xdef\bm#1{\boldsymbol{#1}} \xdef\mcal#1{\mathcal{#1}} \xdef\vv#1{\mathbf{#1}}\xdef\vvp#1{\pmb{#1}} \xdef\ve{\varepsilon} \xdef\l{\lambda} \xdef\th{\vartheta} \xdef\a{\alpha} \xdef\tagged#1{(\text{#1})} \xdef\tagged*#1{\text{#1}} \xdef\tagEqHere#1#2{\href{#2\#eq-#1}{(\text{#1})}} \xdef\tagDeHere#1#2{\href{#2\#de-#1}{\text{#1}}} \xdef\tagEq#1{\href{\#eq-#1}{(\text{#1})}} \xdef\tagDe#1{\href{\#de-#1}{\text{#1}}} \xdef\T#1{\htmlId{eq-#1}{#1}} \xdef\D#1{\htmlId{de-#1}{\vv{#1}}} \xdef\conv#1{\mathrm{conv}\, #1} \xdef\cone#1{\mathrm{cone}\, #1} \xdef\aff#1{\mathrm{aff}\, #1} \xdef\lin#1{\mathrm{Lin}\, #1} \xdef\span#1{\mathrm{span}\, #1} \xdef\O{\mathcal O} \xdef\ri#1{\mathrm{ri}\, #1} \xdef\rd#1{\mathrm{r}\partial\, #1} \xdef\interior#1{\mathrm{int}\, #1} \xdef\proj{\Pi} \xdef\epi#1{\mathrm{epi}\, #1} \xdef\grad#1{\mathrm{grad}\, #1} \xdef\hess#1{\nabla^2\, #1} \xdef\subdif#1{\partial #1} \xdef\co#1{\mathrm{co}\, #1} $$
Subgradient a subdiferenciál
Definice $\D{2.5.1}$ (Subgradient a subdiferenciál)
Nechť $X \subseteq \R^n$ je konvexní množina. Vektor $a \in \R^n$ se nazývá subgradient funkce $f: X \to \R$ v bodě $x^* \in X$, jestliže $$ f(x) - f(x^* ) \geq \scal a {x - x^* } \tag{\T{2.5.1}} $$ pro každé $x \in X$. Množina všech subgradientů funkce $f$ v bodě $x^* $ se nazývá subdiferenciál funkce $f$ v bodě $x^* $ a značí se $\subdif f(x^* )$. Funkce $f$ se nazývá subdiferencovatelná v bodě $x^* $, jestliže $\subdif f(x^* ) \neq \emptyset$.
Jistě platí podle Věty $\tagDeHere{2.4.2}{./konvexni-funkce}$ i $\grad f(x^* ) \in \subdif f(x^* )$
Speciálně, je-li $f:X \subseteq \R \to \R$ konvexní a $x^* \in \ri X$, pak podle Věty $\tagDeHere{2.4.7}{./konvexni-funkce}$ existují jednostranné derivace $f'_ +(x^* ), f'_ -(x^* )$, přičemž platí $f'_ -(x^* ) \leq f'_ +(x^* )$. V tomto případě pak máme $$ \subdif f(x^* ) = [f'_ -(x^* ), f'_ +(x^* )] $$
Věta $\D{2.5.4}$
Nechť $X \subseteq \R^n$ je konvexní množina a $f: X \to \R$
- Je-li funkce $f$ konvexní a $x^* \in \ri X$, pak $\subdif f(x^* )$ je neprázdná, uzavřená a konvexní množina
- Je-li $\subdif f(x)$ neprázdná pro každé $x \in X$, pak $f$ je konvexní na $X$
Fenchelova transformace
Fenchelova transformace je transformace, která k funkci $f: X \subseteq \R^n \to \R$ přiřadí konvexní funkci $f^* : \R^n \to \R$. Této přidružené funkci $f^* $ se v řeči optimalizace/matematického programování říká duální úloha (viz Definice $\tagDeHere{4.3.3}{./dualni-uloha}$).
Definice $\D{2.6.1}$ (Fenchelova transformace)
Nechť $f: \R^n \to \R$. Funkce $$ f^* (y) := \sup_{x \in \R^n} [\scal x y - f(x)] $$ se nazývá Fenchelova transformace funkce $f$ (nebo také (konvexně) konjugovanou funkcí funkce $f$).
Jistě $f: \R^n \to \R \cup \set{\infty}$ a proto definujeme ještě efektivní definiční obor $D^* (f) = \set{x \in D(f) \mid f(x) < \infty}$
Lemma $\D{2.6.3}$
Nechť je dána funkce $f: X \subseteq \R^n \to \R$ a $f^* $ je její Fenchelova transformace. Pak následující tvrzení jsou pravdivá:
- Funkce $f^* $ je konvexní na množině $Y := \set{y \in \R^n \mid f^* (y) < \infty}$
- Pro každé $x \in X$ a $y \in \R^n$ platí tzv. Fenchelova(-Youngova) nerovnost
$$f(x) + f^* (y) \geq \scal x y$$ přičemž rovnost nastane právě tehdy, když $y \in \subdif f(x)$. - Je-li $f(x) \geq g(x)$ na $X$, pak $f^* (y) \leq g^* (y)$ pro všechna $y \in \R^n$.
Věta $\D{2.6.6}$ (Fenchel & Moreau)
Nechť $X \subseteq \R^n$ je konvexní množina a funkce $f: X \to \R$ konvexní na $X$. Pak v každém bodě spojitosti funkce $f$ platí tzv. Fenchelova rovnost $$ f^{** } = f $$
Jinak řečeno, druhá Fenchelova transformace ke konvexní funkci je s touto funkcí totožná, tj. $f^{**} \equiv f$ pro $f$ konvexní. Navíc jelikož $f^* $ je vždy konvexní, tak dostáváme, že počítat třetí Fenchelovu transformaci $f^{* * * }$ nemá smysl, protože bude totožná s první Fenchelovou transformací $f^* $
Definice $\D{2.6.7}$ (Obálka funkce)
Nechť $X \subseteq \R^n$ je konvexní množina a $f: X \to \R$. Potom funkce $$ g(x) := \sup \set{h(x) \mid h \text{ je konvexní a } h(x) \leq f(x) \; \forall x \in X} $$ se nazývá konvexní obálka (obal) funkce $f$ a značí se $\co f$.
Jinak řečeno, $\co f$ je největší konvexní funkce, která je majorizována funkcí $f$
Jistě platí $D(\co f) = \conv (D (f))$, z čehož plyne $\conv (\epi f) \subseteq \epi (\co f)$

Zde $\conv (\epi f) = \epi {|x|} \setminus \set{0}$, ale $0 \in \epi (\co f)$
Věta $\D{2.6.9}$
Nechť $X \subseteq \R^n$ je konvexní množina a $f: X \to \R$. Potom pro každé $x \in \ri X$ platí $$ \co f(x) = f^{* * }(x) $$
Numerické metody v R
$$ \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\norm#1{\left\lVert #1 \right\rVert} \xdef\dist{\rho} \xdef\and{\&}\xdef\brackets#1{\left\{ #1 \right\}} \xdef\parc#1#2{\frac {\partial #1}{\partial #2}} \xdef\mtr#1{\begin{pmatrix}#1\end{pmatrix}} \xdef\bm#1{\boldsymbol{#1}} \xdef\mcal#1{\mathcal{#1}} \xdef\vv#1{\mathbf{#1}}\xdef\vvp#1{\pmb{#1}} \xdef\ve{\varepsilon} \xdef\l{\lambda} \xdef\th{\vartheta} \xdef\a{\alpha} \xdef\tagged#1{(\text{#1})} \xdef\tagged*#1{\text{#1}} \xdef\tagEqHere#1#2{\href{#2\#eq-#1}{(\text{#1})}} \xdef\tagDeHere#1#2{\href{#2\#de-#1}{\text{#1}}} \xdef\tagEq#1{\href{\#eq-#1}{(\text{#1})}} \xdef\tagDe#1{\href{\#de-#1}{\text{#1}}} \xdef\T#1{\htmlId{eq-#1}{#1}} \xdef\D#1{\htmlId{de-#1}{\vv{#1}}} \xdef\conv#1{\mathrm{conv}\, #1} \xdef\cone#1{\mathrm{cone}\, #1} \xdef\aff#1{\mathrm{aff}\, #1} \xdef\lin#1{\mathrm{Lin}\, #1} \xdef\span#1{\mathrm{span}\, #1} \xdef\O{\mathcal O} \xdef\ri#1{\mathrm{ri}\, #1} \xdef\rd#1{\mathrm{r}\partial\, #1} \xdef\interior#1{\mathrm{int}\, #1} \xdef\proj{\Pi} \xdef\epi#1{\mathrm{epi}\, #1} \xdef\grad#1{\mathrm{grad}\, #1} \xdef\hess#1{\nabla^2\, #1} \xdef\subdif#1{\partial #1} \xdef\co#1{\mathrm{co}\, #1} $$
Rychlost konvergence
Definice $\D{3.1}$
Nechť jsou dány 2 posloupnosti $\brackets{e_ k}_ {k = 0}^\infty$ a $\brackets{h_ k}_ {k = 0}^\infty$ takové, že $$ e_k \in [0, \infty), \quad e_k \to 0 \quad \and \quad h_k \in [0, \infty), \quad h_k \to 0. $$ Řekneme, že posloupnost $\brackets{e_k}$ konverguje rychleji (pomaleji) než $\brackets{h_k}$, pokud existuje index $\tilde k \in \N_0$ takový, že $$ e_k \leq_{(\geq)} h_k \quad \forall k \in [\tilde k, \infty) \cap \N_0 $$
Definice $\D{3.2}$ (Rychlost konvergence)
Nechť je dána posloupnost $\brackets{e_ k}_ {k = 0}^\infty$ splňující $e_k \in [0, \infty)$ a $e_k \to 0$. Řekneme, že posloupnost $\brackets{e_k}$ konverguje
-
alespoň lineárně s rychlostí $\beta \in (0,1)$, pokud konverguje rychleji než geometrická posloupnost se členy tvaru $q \bar \beta^k$, kde $q > 0$ a $\bar \beta \in (\beta, 1)$.
- čím větší $\bar \beta$, tím pomaleji jde tato geometrická posloupnost k nule - tj. konverguje rychleji než geometrická posloupnost s $\bar \beta$ větší než $\beta$
- nejvýše lineárně s rychlostí $\beta \in (0,1)$, pokud konverguje pomaleji než geometrická posloupnost se členy tvaru $q \bar \beta^k$, kde $q > 0$ a $\bar \beta \in (0, \beta)$.
- lineárně s rychlostí $\beta \in (0,1)$, pokud konverguje nejvýše a současně alespoň lineárně s rychlostí $\beta$.
- superlineárně (sublineárně), pokud konverguje rycheji (pomaleji) než libovolná geometrická posloupnost se členy tvaru $q \beta^k$, kde $q > 0$ a $\beta \in (0,1)$.
Definice $\D{3.4}$
Nechť je dána posloupnost $\brackets{e_ k}_ {k = 0}^\infty$ splňující $e_k \in [0, \infty)$ a $e_k \to 0$, přičemž $\brackets{e_k}$ konverguje superlineárně. Řekneme, že posloupnost $\brackets{e_k}$ konverguje
-
alespoň superlineárně s řádem $p > 1$, pokud konverguje rychleji než všechny posloupnosti se členy tvaru $q \beta^{\bar p^k}$, kde $q > 0$ a $\beta \in (0,1)$ a $\bar p \in (1, p)$
- čím větší $\bar p$, tím rychleji posloupnost $q \beta^{\bar p^k}$ konverguje - tj. $\brackets{e_k}$ konverguje rychleji než všechny posloupnosti s menším $p$
- nejvýše superlineárně s řádem $p > 1$, pokud konverguje pomaleji než všechny posloupnosti se členy tvaru $q \beta^{\bar p^k}$, kde $q > 0$ a $\beta \in (0,1)$ a $\bar p \in (p, \infty)$
- superlineárně s řádem $p > 1$, pokud konverguje nejvýše a současně alespoň superlineárně s řádem $p$.
- superlineárně s řádem $p = 1$, pokud konverguje pomaleji než všechny posloupnosti se členy tvaru $q \beta^{\bar p^k}$, kde $q > 0$ a $\beta \in (0,1)$ a $\bar p \in (1, \infty)$
Metody
Definice $\D{3.1.1}$ (Unimodální funkce)
Nechť je dán interval $I \subset \R$ a funkce $f: I \to \R$. Řekneme, že $f$ je unimodální na $I$, jestliže existuje $x^* \in I$ takové, že
- $f(x_1) > f(x_2)$ pro libovolná $x_1, x_2 \in I$ splňující $x^* > x_1 > x_2$
- $f(x_1) < f(x_2)$ pro libovolná $x_1, x_2 \in I$ splňující $x^* < x_1 < x_2$
Jinými slovy, unimodální funkce je klesající na $(-\infty, x^* ) \cap I$ (tj. nalevo od $x^* $) a rostoucí na $I \cap (x^* , \infty)$ (tj. napravo od $x^* $).
Unimodalita neimplikuje konvexnost (ani se spojitostí), pouze kvazikonvexnost
Naopak, konvexní funkce nemusí nutně být unimodální (ale ostrá konvexnost $\implies$ unimodalita)
Konvexní funkce nemusí být např. jen rostoucí, ale i neklesající
V této části budeme řešit úlohu $$ f(x) \to \min, \qquad x \in I := [a,b] \tag{\T{3.1.1}} $$
Lemma $\D{3.1.2}$
Nechť $f: I \to \R$ je unimodální na $I$ a $x_1, x_2 \in I$ jsou takové, že $x_1 < x_2$.
- Je-li $f(x_1) \leq f(x_2)$, pak $x^* \leq x_2$
- Je-li $f(x_1) \geq f(x_2)$, pak $x^* \geq x_1$
Upozornění:
Dále uvažujme POUZE UNIMODÁLNÍ funkce.
Metoda prostého dělení
Tato metoda není efektivní a je to de facto hrubá síla
Podle parity $N$ určíme dělící body intervalu $I$.
| $N$ liché | $N$ sudé |
|---|---|
| $$x_i := a + {b - a \over N + 1} i, \quad i=1, \dots, N = 2k - 1$$ | $$x_{2i} := a + {b - a \over k + 1} i \quad \and \quad x_{2i - 1} := x_{2i} - \delta, \ i = 1, \dots, k := N/2,$$ |
kde $\delta$ je vhodné malé číslo.
Poté vyčíslíme $f(x_1), \dots, f(x_N)$ (což v případě $N$ sudého a $\delta \in \set{0, {b-a \over k+ 1}}$ znamená pouze $k$ vyčíslení) a nechť v $x_j$ nastává nejmenší hodnota, tj. $$ f(x_j) = \min_{1 \leq i \leq N} f(x_i) $$ Pak z Lemma $\tagDe{3.1.2}$ plyne, že $x^* \in [x_{j-1}, x_{j+1}]$ a tento interval nazveme interval lokalizace minima (ILM) a za aproximaci $x^* $ vezmeme střed ILM, tj. $\bar x := {x_{j-1} + x_{j+1} \over 2}$
Pro délku $l_N$ intervalu lokalizace minima platí $$ l_N := \max_{1 \leq i \leq N} (x_{i+1} - x_{i-1}) = \begin{cases} 2 {b - a \over N+1}, & N = 2k - 1 \ {b - a \over (N/2) + 1} + \delta, & N = 2k \end{cases} $$
Pro $N$ sudé je poslední interval delší, proto dostáváme takový tvar $l_N$
Přesnost této metody je dána polovinou ILM, tj. ${l_N \over 2}$
Rychlost konvergence této metody je sublineární, navíc je tento algoritmus pasivní, tj. volba $x_{m+1}$ nezáleží na $x_1, \dots, x_m$ (závisí pouze na $N$, či na $N$ a $\delta$).
Při rovnosti funkčních hodnot preferujeme konec (teoreticky by to mělo být jedno)
Metoda půlení intervalu
Nechť nyní $N = 2k$. Položme $a_0 = a$, $b_0 = b$ a $$ x_i^- := {a_{i-1} + b_{i-1} \over 2} - \delta \quad \and \quad x_i^+ := {a_{i-1}+b_{i-1} \over 2} + \delta, $$ kde $\delta > 0$ je dostatečně malé a $i = 1, \dots, k$. Vyčíslíme funkci v $x_i^-, x_i^+$, tj. dostaneme $f(x_i^-), f(x_i^+)$. Pak
- jestliže $f(x_i^-) < f(x_i^+)$, pak podle Lemma $\tagDe{3.1.2}$ je ILM $[a_{i-1}, x_i^+] \implies a_i = a_{i-1}, b_i = x_i^+$
- jestliže $f(x_i^-) > f(x_i^+)$, pak podle Lemma $\tagDe{3.1.2}$ je ILM $[x_i^-, b_{i-1}] \implies a_i = x_i^-, b_i = b_{i-1}$
Takto můžeme tento proces opakovat ($k$-krát, jelikož máme $N = 2k$ povolených vyčíslení), kdy za $a,b$ volíme krajní body ILM pro každý krok. Zřejmě, jako aproximaci $x^* $ v $k$-tém kroku bereme střed ILM pro $k$-tý krok.
Délka ILM je v tomto případě $$ l_k = {b - a\over 2^k} + {(2^k - 1)\delta \over 2^{k-1}}, $$ přičemž $\delta \in [0, {b-a\over 2}]$ a navíc pro $k \to \infty$ je $l_k \to 2\delta$.
Z tohoto vyplývá, že čím menší $\delta$, tím je metoda přesnější. Nicméně ve skutečnosti se můžeme dostat k zaokrouhlovacím chybám, které dokonce mohou způsobit, že špatně určíme velikosti $f(x_i^-), f(x_i^+)$ (tím pádem bychom řekli, že $x^* $ je v opačném intervalu, než je ve skutečnosti)
Tato metoda konverguje lineárně s rychlostí $1/2$.
Při rovnosti funkčních hodnot zapomínáme konec (teoreticky by to mělo být jedno)
Metoda zlatého řezu
Myšlenka metody zlatého řezu "vylepšuje" metodu půlení intervalu tak, že každá další iterace umožňuje pouze jedno další vyčíslení.
Zde $\tau$ je řešení rovnice $\tau^2 - \tau - 1 = 0$, tj. a $\frac 1 \tau \approx 0.618$
Mějme funkci $f$, interval $[a,b]$, přesnost $\ve$ nebo počet vyčíslení $N \geq 2$:
- (Inicializace) Položíme $a_0 := a, b_0 := b$ a $k := 1$. Vypočteme
$$\l_1 := a_0 + {b_0 - a_0 \over \tau^2} \quad \and \quad \mu_1 := a_0 + {b_0 - a_0 \over \tau}$$ - Je-li $k = N$, pokračujeme částí 5., jinak následuje krok 3.
- Vyčíslíme $f(\l_k)$ a $f(\mu_k)$. Jestliže $f(\l_k) \geq f(\mu_k)$:
- Položíme $a_k := \l_k, b_k = b_{k-1}, \l_{k+1} := \mu_k$ a
$$f(\l_{k+1}) := f(\mu_k), \quad \mu_{k+1} := a_k + {b_k - a_k \over \tau}$$ a pokračujeme na krok 4. - Položíme $a_k := a_{k-1}, b_k := \mu_k, \mu_{k+1} := \l_k$ a
$$f(\mu_{k+1}) := f(\l_k), \quad \l_{k+1} := a_k + {b_k - a_k \over \tau^2}$$ a pokračujeme na krok 4.
- Položíme $a_k := \l_k, b_k = b_{k-1}, \l_{k+1} := \mu_k$ a
- Položíme $k := k+1$ a pokračujeme krokem 2.
- Stanovíme poslední ILM jako $[a_{k-1}, b_{k-1}]$ a vypočteme $\bar x := {a_{k-1} + b_{k-1} \over 2}$. KONEC
Tato metoda konverguje lineárně s rychlostí $\frac 1 \tau \approx 0.618$
Toto neznamená, že by na stejný počet vyčíslení byla tato metoda horší než metoda půlení intervalu

Fibonacciho metoda
V této poslední metodě uvažujme, že zkrácení $\delta$ může být jiné v každé kroku metody.
Nechť $F_n$ je $n$-té Fibonacciho číslo
Máme povoleno $N$ vyčíslení, takže $M = N - 1$ a $$ \l_i = a_{i - 1} + {F_{N - i -1} \over F_{N - i + 1}} l_{i-1} = b_{i-1} - {F_{N - 1} \over F_{N - 1 + i}} l_{i-1} $$ $$ \mu_i = a_{i-1} + {F_{N - 1} \over F_{N - 1 + i}} l_{i-1} = b_{i-1} - {F_{N - i -1} \over F_{N - i + 1}} l_{i-1} $$

Tato metoda konverguje lineárně s rychlostí $\frac 1 \tau \approx 0.618$, tj. stejně jako metoda zlatého řezu
Fibonacciho metoda je (mírně) přesnější, než metoda zlatého řezu (která lze vnímat jako limitní varianta Fibonacciho metody). Nicméně u Fibonacciho metody je při změně $N$ potřeba všechny body přepočítat, což u metody zlatého řezu není.
Numerické metody v R^n
$$ \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\norm#1{\left\lVert #1 \right\rVert} \xdef\dist{\rho} \xdef\and{\&}\xdef\brackets#1{\left\{ #1 \right\}} \xdef\parc#1#2{\frac {\partial #1}{\partial #2}} \xdef\mtr#1{\begin{pmatrix}#1\end{pmatrix}} \xdef\bm#1{\boldsymbol{#1}} \xdef\mcal#1{\mathcal{#1}} \xdef\vv#1{\mathbf{#1}}\xdef\vvp#1{\pmb{#1}} \xdef\ve{\varepsilon} \xdef\l{\lambda} \xdef\th{\vartheta} \xdef\a{\alpha} \xdef\vf{\varphi} \xdef\Tagged#1{(\text{#1})} \xdef\tagged*#1{\text{#1}} \xdef\tagEqHere#1#2{\href{#2\#eq-#1}{(\text{#1})}} \xdef\tagDeHere#1#2{\href{#2\#de-#1}{\text{#1}}} \xdef\tagEq#1{\href{\#eq-#1}{(\text{#1})}} \xdef\tagDe#1{\href{\#de-#1}{\text{#1}}} \xdef\T#1{\htmlId{eq-#1}{#1}} \xdef\D#1{\htmlId{de-#1}{\vv{#1}}} \xdef\conv#1{\mathrm{conv}\, #1} \xdef\cone#1{\mathrm{cone}\, #1} \xdef\aff#1{\mathrm{aff}\, #1} \xdef\lin#1{\mathrm{Lin}\, #1} \xdef\span#1{\mathrm{span}\, #1} \xdef\O{\mathcal O} \xdef\ri#1{\mathrm{ri}\, #1} \xdef\rd#1{\mathrm{r}\partial\, #1} \xdef\interior#1{\mathrm{int}\, #1} \xdef\proj{\Pi} \xdef\epi#1{\mathrm{epi}\, #1} \xdef\grad#1{\mathrm{grad}\, #1} \xdef\gradT#1{\mathrm{grad}^T #1} \xdef\gradx#1{\mathrm{grad}_x #1} \xdef\hess#1{\nabla^2\, #1} \xdef\hessx#1{\nabla^2_x #1} \xdef\jacobx#1{D_x #1} \xdef\jacob#1{D #1} \xdef\subdif#1{\partial #1} \xdef\co#1{\mathrm{co}\, #1} \xdef\iter#1{^{[#1]}} \xdef\str{^*} \xdef\spv{\mcal V} \xdef\civ{\mcal U} \xdef\knvxProg{\tagEqHere{4.1}{./nutne-a-postacujici-podminky-optimality} \, \and \, \tagEqHere{4.2}{nutne-a-postacujici-podminky-optimality}} $$
Budeme se věnovat úlohám (přesněji numerickým metodám jejich řešení) typu $$ f(x) \to \min, \quad x \in \R^n, \tag{\T{3.2.1}} $$ kde $f:\R^n \to \R$ je (jednou/dvakrát/třikrát) spojitě diferencovatelná funkce. Obecně jsou metody numerické optimalizace založeny na minimalizační posloupnosti $\brackets{x^{[k]}}$ definované jako $$ x^{[k+1]} = x^{[k]} + \a_k h_k, $$ kde $\a_k \in \R$ se nazývá délka $k$-tého kroku a vektor $h_k \in \R^n$ je směr $k$-tého vektoru.
Budeme uvažovat tzv. přesnou minimalizaci, kdy dílčí minimalizace řešíme přesně (nikoliv numerickými metodami)
Všechny následující metody jsou spádové
Metoda největšího spádu
U této metody volíme $$ h_k = - \grad f(x^{[k]}), $$ přičemž délku kroku volíme přesným řešením úlohy $$ f(x^{[k+1]}) = f(x^{[k]} - \a_k \grad f(x^{[k]})) = \min_{\a \geq 0} f(x^{[k]} - \a \cdot \grad f(x^{[k]})) $$ Dále bude platit, že vektory určené body $x^{[k+1]}, x^{[k]}$ a $x^{[k+2]}, x^{[k+1]}$ jsou na sebe ortogonální. Z tohoto dostáváme, že pro daný směr hledáme nejblížší vrstevnici, která bude tečná k tomuto vektoru.
Tato metoda je prvního řádu (stačí nám pouze gradient).
V některých případech dochází k tzv. "cik-cak" efektu (klikatěni), kdy se minimalizující posloupnost dostává k optimu velmi pomalu. Toto se děje například u Rosenbrockovy (banánové) funkce (jedna z testovacích funkcí)
Kvadratické funkce
Nechť $f$ je kvadratická funkce tvaru $$ f(x) = \frac 1 2 \scal {Qx} x - x^T b \tag{\T{3.2.2}}, $$ kde $Q = Q^T > 0$ je symetrická $n \times n$ matice a $b \in \R^n$. Taková funkce $f$ je ostře (i silně) konvexní. Z pozitivní definitnosti $Q$ dostáváme, že vlastní čísla matice $Q$ jsou kladné a můžeme je uspořádat následovně $$ 0 < \l_1 \leq \l_2 \leq \dots \leq \l_n $$ Díky tomu můžeme úlohu $\tagEq{3.2.1}$ vyřešit "přímo" jako $x^* = Q^{-1} b$, nicméně počítání inverze může být velice náročné (výpočetně).
V tomto případě je gradient $g$ funkce $f$ dán jako $$ g(x) := \grad f(x) = Qx - b, $$ tedy v jednotlivých iteracích dostáváme $g_k := Qx^{[k]} - b$ a $\a_k$ můžeme určit jako $$ \a_k = {g_k^T g_k \over g_k^T Q g_k} \in [1/\l_n, 1/\l_1] $$
Nyní se zaměříme na konvergenci metody, kterou můžeme zkoumat pomocí $$ E(x) := f(x) - f(x^* ) = \frac 1 2 (x - x^* )^T Q (x - x^* ) $$
Lemma $\D{3.2.1}$ (Konvergence metody největšího spádu)
Platí $$ E(x^{[k+1]}) = \left(1 - {(g_k^T g_k)^2 \over (g_k^T Q g_k)(g_k^T Q^{-1} g_k)} \right) E(x^{[k]}) $$
Z Lemmatu $\tagDe{3.1.2}$ okamžitě plyne, že pokud pro nějaké $k \in \N$ nastane $$ 1 = {(g_k^T g_k)^2 \over (g_k^T Q g_k)(g_k^T Q^{-1} g_k)}, \tag{\T{3.2.1-a}} $$ tak v $k+1$ metoda největšího spádu nalezne řešení přesně. V opačném případě je metoda nekonečně-kroková.
Rovnost $\tagEq{3.2.1-a}$ nastane v případě, že $g_k$ je vlastním vektorem matice $Q$, jinak řečeno gradient musí mířit do středu elipsy (elipsoidu).
V případě, že $\l_1 = \dots = \l_n$ je konvergence superlineární. Naopak pokud $\l_1 = \dots = \l_{n-1} \neq \l_n$, tak může být konvergence velice pomalá. Ve skutečnosti ještě rychlost konvergence závisí na počátečním $x^{[0]}$
Nekvadratické funkce
V případě nekvadratické funkce je metoda největšího spádu schopna nalézt pouze stacionární body.
Lemma $\D{3.2.2iii}$ (Lokální konvergence)
Nechť $f: \R^n \to \R$ je spojitě diferencovatelná. Jestliže bod $x^{[0]} \in \R^n$ je takový, že množina $$ \set{x \in \R^n \mid f(x) \leq f(x^{[0]})} $$ je ohraničená, pak posloupnost $\brackets{x^{[k]}}$ generovaná metodou největšího spádu konverguje k bodu $x^* $, kde $\grad f(x^* ) = 0$.
Pokud konverguje $\brackets{x^{[k]}}$ k bodu $x^* $ a funkce $f$ je dvakrát spojitě diferencovatelná na okolí $x^* $ a platí $$ aI \leq \hess f(x^* ) \leq AI, $$ kde $a, A > 0$ (tedy $f$ je v okolí $x^* $ silně konvexní), pak metoda konverguje (alespoň) s rychlostí $\left(A - a \over A + a\right)^2$
Tedy i pro nekvadratické funkce hraje velkou roli podmíněnost matice $\hess f(x^* )$
Metoda největšího spádu se nejčastěji využívá v jiných metodách jako pomocné, když ony metody samotné v tu chvíli neposkytují dostatečné zlepšení
Celkem můžeme metodu největšího spádu shrnout:
- globální konvergence (pro nekvadratické metody za dalších předpokladů)
-
pomalá konvergence
- mnohdy numericky ani nekonverguje
- je základem pro další (lepší) metody
Newtonova metoda
Hlavní myšlenkou Newtonovy metody je, že v $(k+1)$-kroku, kde $k \in \N_0$, funkci $f$ aproximujeme Taylorovým polynomem druhého řádu se středem v bodě $x^{[k]}$ a jako $x^{[k+1]}$ volíme bod, ve kterém tento polynom nabývá svého minima.
Jinak řečeno místo tečné nadroviny k funkci konstruujeme tečnou $n$-rozměrnou parabolu
Tedy místo funkce $f$ uvažujeme v $k$-tém kroku $$ T_k(x) := f(x^{[k]}) + \grad f(x^{[k]}) (x - x^{[k]}) + \frac 1 2 (x - x^{[k]})^T \hess f(x^{[k]}) (x - x^{[k]}) \approx f(x) $$
Jelikož hledáme řešení $T_k(x) \to \min$, tak výraz výše první zderivujme, z čehož dostaneme $$ \grad T_k(x) = \grad f(x^{[k]}) + \hess f(x^{[k]}) (x - x^{[k]}), $$ což v případě regulární matice $\hess f(x^{[k]})$ vede na $$ x^{[k+1]} = x^{[k]} - (\hess f(x^{[k]}))^{-1} \grad f(x^{[k]}) $$
Pro $\hess f(x) > 0$ je funkce konvexní a nalezneme minimum
Nicméně je důležité podotknout, že výpočet $(\hess f(x^{[k]}))^{-1}$ je velmi výpočetně náročný. Avšak v případě kvadratické funkce Newtonova metoda nalezne řešení v jednom kroku, tedy její rychlost konvergence je superlineární s řádem $\infty$.
Regularita matice $\hess f(x^{[k]})$ je velmi důležitá pro konvergenci, viz následující věta.
Věta $\D{3.2.5}$
Nechť $f \in C^3$ v okolí bodu $x^* \in \R^n$, který je nedegenerovaným minimem, tj. $\grad f(x^* ) = 0$ a $\hess f(x^* ) > 0$. Potom pro $x^{[0]} \in \R^n$ dostatečně blízko $x^* $ konverguje $\brackets{x^{[k]}}$ generovaná Newtonovou metodou k bodu $x^* $ superlineárně s řádem (alespoň) $p = 2$ (tj. kvadraticky).
Zde určit, co znamená "dostatečně blízko $x^* $" je obtížné
Celkem můžeme Newtonovu metodu shrnout jako:
- velmi rychlá konvergence
- nutnost dostatečně blízké počáteční aproximace
- velmi velká výpočetní náročnost při velkém $n$ (počtu dimenzí)
Metoda sdružených gradientů
Uvažujme situaci v úloze $\tagEq{3.2.1}$, kdy máme funkci $$ f(x) = \frac 1 2 x^T Q x - b^T x \tag{\T{MSG}}, $$ kde $Q = Q^T \in \R^{n \times n}, Q > 0$ je symetrická matice a $b \in \R^n$.
Pak nalezení úlohy $\tagEq{3.2.1} \; \and \; \tagEq{MSG}$ je ekvivalentní s řešením úlohy $$ Qx = b \tag{\T{MSGa}}, $$ kterou umíme řešit například Gaussovou eliminací.
Metoda sdružených gradientů je v případě $Q > 0$ přímou metodou, která dojde k řešení $\tagEq{MSGa}$ po $n$ krocích. Nicméně tento fakt lze brát také jako, že je to iterační metoda s velmi rychlou konvergencí v případě pozitivně definitní matice.
Definice $\D{3.2.7}$ ($Q$-sdružené vektory)
Nechť $Q = Q^T \in \R^{n \times n}$ je pozitivně definitní. Vektory $h_1, h_2 \in \R^n \setminus \set{0}$ se nazývají $Q$-sdružené (nebo také $Q$-ortogonální), jestliže $$ \scal {Qh_1} {h_2} = h_1^T Q h_2 = 0 $$ Systém vektorů $\set{h_0, \dots, h_{m-1}}$ v $\R^n \setminus \set{0}$ pro $m \in \set{2, \dots, n}$ se nazývá $Q$-sdružený, jestliže $$ \scal {Q h_i} {h_j} = 0 \text{ pro } i \neq j $$
Věta $\D{3.2.8}$
Nechť systém vektorů $\set{h_0, \dots, h_{m-1}}$ v $\R^n \setminus \set{0}$ s $m \in \set{2, \dots, n}$ je $Q$-sdružený. Potom jsou tyto vektory lineárně nezávislé.
Věta $\D{3.2.9}$
Nechť $m \in \set{2, \dots, n}$ a mějme systém $Q$-sdružených vektorů $\set{h_0, \dots, h_{m-1}}$ v $\R^n$. Nechť $x \iter 0$ je dáno a body $x \iter 1, \dots, x \iter m$ jsou dány jako $$ x \iter {k+1} = x \iter k + \a_k h_k = x \iter 0 + \sum_{i = 0}^k \a_i h_i, \quad k \in \set{0, \dots, m-1}, \tag{\T{3.2.8}} $$ kde $\a_k$ jsou volena tak, že $f(x \iter k + \a_k h_k) = \min_{\a \in \R} f(x \iter k + \a h_k)$ pro $k \in \set{0, \dots, m-1}$ (tj. jsou volena přesnou minimalizací). Pak pro kvadratickou funkci $f$ definovanou v $\tagEq{MSG}$ platí $$ f(x \iter m) = \min_{x \in X_m} f(x), $$ kde $X_m := \lin \set{h_0, \dots, h_{m-1}}$ (viz Definice $\tagDeHere{2.1.6}{./konvexni-mnoziny}$ - lineární obal). Zejména pro $m = n$ dostáváme $$ f(x \iter n) = \min_{x \in \R^n} f(x), $$ tj. $x \iter n$ je řešením úlohy $\tagEq{3.2.1} \; \and \; \tagEq{MSG}$.
Nalezení $Q$-sdružených vektorů lze provést zobecněným Gramm-Schmidtovým ortogonalizačním procesem (ten je uveden v Lin. Alg. ve speciálním tvaru pro $Q = I$).
Explicitně můžeme odvodit délku $k$-tého kroku jako $$ \a_k = - {h_k^T \grad f(x \iter k) \over h_k^T Q h_k} \tag{\T{3.2.9}} $$
Celkem můžeme metodu popsat následovně $$ h_0 := -\grad f(x \iter 0), \quad h_k := -\grad f(x \iter k) + \beta_{k-1} h_{k-1} \tag{3.2.10} $$ $$ \beta_{k-1} := {\gradT f(x \iter k) Q h_{k-1} \over h_{k-1}^T Q h_{k-1}} \tag{3.2.11}, $$ přičemž body minimalizující posloupnosti jsou počítány podle Věty $\tagDe{3.2.9}$.
Tento výpočet lze "zjednodušit", viz $\Tagged{3.2.12}$ v přednášce.
Hlavní výhodou metody sdružených gradientů je její snadná implementace, naopak nevýhodou citlivost na podmíněnost matice $Q$. Také se daří říct, že metoda sdružených gradientů konverguje nejrychleji z metod založených pouze na maticovém násobení.
Pro nekvadratické funkce používáme stejný algoritmus jako doteď až na volbu $\beta_k$, ale metodu restartujeme po $n$ krocích
Věta $\D{3.2.13}$ (Rychlost konvergence)
Nechť $f \in C^3$ na $\R^n$, $x \iter 0 \in \R^n$ a $x^* $ je nedegenerované lokální minimum, tj. $\grad f(x^* ) = 0$ a $\hess f(x^* ) > 0$ Nechť $x \iter k$ je výsledek metody sdružených gradientů s cyklem délky $n$ a výchozím bodem $x \iter {k-1}$ a nechť $x \iter k \to x\str$ pro $k \to \infty$. Potom minimalizující posloupnost $\set{x \iter k}$ konverguje superlineárně s řádem alespoň $p = 2$.
MSG souvisí s metodami Krylovových podprostorů.
Nutné a postačující podmínky optimality
$$ \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\norm#1{\left\lVert #1 \right\rVert} \xdef\dist{\rho} \xdef\and{\&}\xdef\brackets#1{\left\{ #1 \right\}} \xdef\parc#1#2{\frac {\partial #1}{\partial #2}} \xdef\mtr#1{\begin{pmatrix}#1\end{pmatrix}} \xdef\bm#1{\boldsymbol{#1}} \xdef\mcal#1{\mathcal{#1}} \xdef\vv#1{\mathbf{#1}}\xdef\vvp#1{\pmb{#1}} \xdef\ve{\varepsilon} \xdef\l{\lambda} \xdef\th{\vartheta} \xdef\a{\alpha} \xdef\Tagged#1{(\text{#1})} \xdef\tagged*#1{\text{#1}} \xdef\tagEqHere#1#2{\href{#2\#eq-#1}{(\text{#1})}} \xdef\tagDeHere#1#2{\href{#2\#de-#1}{\text{#1}}} \xdef\tagEq#1{\href{\#eq-#1}{(\text{#1})}} \xdef\tagDe#1{\href{\#de-#1}{\text{#1}}} \xdef\T#1{\htmlId{eq-#1}{#1}} \xdef\D#1{\htmlId{de-#1}{\vv{#1}}} \xdef\conv#1{\mathrm{conv}\, #1} \xdef\cone#1{\mathrm{cone}\, #1} \xdef\aff#1{\mathrm{aff}\, #1} \xdef\lin#1{\mathrm{Lin}\, #1} \xdef\span#1{\mathrm{span}\, #1} \xdef\O{\mathcal O} \xdef\ri#1{\mathrm{ri}\, #1} \xdef\rd#1{\mathrm{r}\partial\, #1} \xdef\interior#1{\mathrm{int}\, #1} \xdef\proj{\Pi} \xdef\epi#1{\mathrm{epi}\, #1} \xdef\grad#1{\mathrm{grad}\, #1} \xdef\gradT#1{\mathrm{grad}^T #1} \xdef\gradx#1{\mathrm{grad}_x #1} \xdef\hess#1{\nabla^2\, #1} \xdef\hessx#1{\nabla^2_x #1} \xdef\subdif#1{\partial #1} \xdef\co#1{\mathrm{co}\, #1} \xdef\iter#1{^{[#1]}} \xdef\str{^*} \xdef\spv{\mcal V} \xdef\civ{\mcal U} $$
Obecný úvod
Úlohou matematického programování nazveme $$ f(x) \to \min, \quad x \in X \tag{\T{4.1}} $$ kde přípustná množina $X$ je zadána systém rovností a nerovností $$ X := \set{x \in P \subseteq \R^n \mid g_i(x) \leq 0, \; g_j(x) = 0, \; i = 1, \dots, k, \; j = k+1, \dots, m} \tag{\T{4.2}} $$
Zde je důležité podotknout, že vždy chceme nerovnostní omezení pouze tvaru $\bm{g_i(x) \leq 0}$
Je dobré si zapatovat, že
- $m$ - počet omezení
- $k$ - počet nerovností (tzn. $g_1, \dots, g_k$ jsou nerovnosti, zbytek rovnosti)
Omezení zakomponovaná v $P$ se nazývají přímá, naopak omezení ve formě $g_l$ se nazývají funkcionální. Dále definujme
-
množinu přípustných vektorů
$$\spv(x^* , X) := \set{h \in \lin X \mid \exists \, \a_0 > 0 : x^* + th \in X \text{ pro } \forall t \in (0, \a_0)}$$- je to kužel
-
množinu spádových vektorů (kužel zlepšujících vektorů)
$$\civ(x^* , f) := \set{h \in \lin X \mid \exists \, \a_0 > 0 : x^* + th \in D(f) \; \and \; f(x^* + th) < f(x^* ) \text{ pro } \forall t \in (0, \a_0)}$$

Lemma $\D{4.1.1}$
Nechť $X \subseteq \R$ a $f: X \to \R$ jsou dány. Je-li bod $x^* \in X$ lokálním řešením úlohy $\tagEq{4.1}$, potom $$ \spv (x^* , X) \cap \civ (x^* , f) = \emptyset $$
Definice $\D{4.1.2}$ (Stacionární bod)
Nechť množina $X \subseteq \R^n$ je konvexní a funkce $f: X \to \R$ je diferencovatelná na (nějaké otevřené množině obsahující) $X$. Řekneme, že bod $x^* \in X$ je stacionárním bodem úlohy $\tagEq{4.1}$ (nebo také stacionárním bodem funkce $f$ na množině $X$), jestliže $$ \scal {\grad f(x^* )} {x - x^* } \geq 0 \tag{\T{4.1.2}}, $$ pro každé $x \in X$.
Výraz v $\tagEq{4.1.2}$ je směrová derivace $x^* $ do libovolného bodu v $X$ - v těchto směrech musí být $f$ neklesající
Pro $X = \R^n$ je podmínka $\tagEq{4.1.2}$ splněna pouze v případě $\grad f(x^* ) = 0$
Dále ukažme, že stacionární bod ve smyslu Definice $\tagDe{4.1.2}$ má vlastnosti, které od něj očekáváme.
Věta $\D{4.1.3}$ (Vlastnosti stacionárního bodu)
Nechť $f: X \to \R$ je diferencovatelná na (nějaké otevřené množině obsahující konvexní množinu) $X \subseteq \R^n$.
- Je-li $x^* \in X$ lokálním extrémem funkce $f$ na $X$ (tj. lokálním řešením úlohy $\tagEq{4.1}$), pak $x^* $ je stacionárním bodem funkce $f$ na $X$
- Naopak, je-li $f$ (ostře) konvexní na $X$ a $x^* \in X$ je stacionárním bodem $f$ na $X$, pak $x^* $ je (jediným) řešením úlohy $\tagEq{4.1}$, tj. (jediným) globálním minimem $f$ na $X$.
Pokud avšak $f$ není konvexní, potřebujeme o rozhodnutí "extrémnosti" stacionárního bodu další nástroje
Nutná podmínka pro $\tagEq{4.1}$
Je-li $x^* \in X$ lokálním minimem funkce $f: X \to \R, \; f \in C^2$, na konvexní množině $X \subseteq \R^n$, pak $$ (x - x^* )^T \hess f(x^* )(x - x^* ) \geq 0 $$ pro všechna $x \in X$ taková, že $\gradT f(x^* )(x - x^* ) = 0$, tj. pro vektory $(x - x^* )\in \ker\gradT f(x^* )$
Postačující podmínka pro $\tagEq{4.1}$
Bod $x^* $ je lokálním minimem funkce $f: X \to \R, f \in C^2$, na konvexní množině $X \subseteq \R^n$, jestliže $$ \gradT f(x^*) (x - x^*) \geq 0, \; \forall x \in X, $$ (tj. je to stacionární bod ve smyslu Definice $\tagDe{4.1.2}$), množina $X$ je polyedr a platí $$ (x - x^*)^T \hess f(x^*) (x - x^*) > 0 $$ pro všechna $x \in X$ taková, že $x \neq x^* $ a $(x - x^* ) \in \ker \gradT f(x^* )$
Je-li $X$ polyedr, pak je $\spv (x^* , X)$ uzavřená
Nutné a postačující podmínky optimality
Uvažujme přidruženou Lagrangeovu funkci $L: P \times \R \times \R^m \to \R$ k úloze $\tagEq{4.1} \; \and \; \tagEq{4.2}$ definovanou jako $$ L(x, y_0, y) := y_0 f(x) + \sum_{i = 1}^m y_i g_i(x), \tag{\T{4.1.2}} $$ přičemž v případě $y_0 = 1$ bude $L(x, 1, y) := L(x,y)$. Navíc čísla $y_0, \dots, y_m$ nazyváme Lagrangeovými multiplikátory.
Omezení nazveme aktivní, pokud se realizuje jako rovnost
Dále ještě zaveďme následující $$ Q := \set{y = (y_1, \dots, y_m)^T \mid y_1, \dots, y_k \geq 0} $$ a dvě další množiny:
-
Množinu aktivních omezení v bodě $x \str$
$$I(x \str) := \set{i \in \set{1, \dots, k} \mid g_i(x \str) = 0}, \quad x \str \in X$$ - Množinu indexů všech funkcí, které se v bodě $x\str$ realizují jako rovnost $$S(x \str) := I(x\str) \cup \set{k+1, \dots, m}, \quad x \str \in X$$
Věta $\D{4.2.1}$ (Lagrangeův princip)
Nechť množina $P \subseteq \R^n$ je konvexní, funkce $f, g_1, \dots, g_k : P \to \R$ jsou diferencovatelné v bodě $x^* \in X$ a $g_{k+1}, \dots, g_m$ jsou spojitě diferencovatelné na nějakém okolí bodu $x^* $. Je-li bod $x^* \in X$ lokálním řešením úlohy $\tagEq{4.1} \; \and \; \tagEq{4.2}$, pak existují Lagrangeovy multiplikátory $y_0\str > 0$ a $y\str \in Q$ takové, že ne všechna $y_0 \str, \dots, y_m \str$ jsou nulová a platí $$ \scal {\gradx L(x\str, y_0\str, y\str)} {x - x\str} \geq 0 \quad \forall x \in P \tag{\T{4.2.3}} $$ $$ y_i\str g_i(x\str) = 0, \quad i = 1, \dots, m \tag{\T{4.2.4}} $$
Podmínka $\tagEq{4.2.3}$ znamená, že $x\str$ musí být stacionárním bodem funkce $L(x, y_0\str, y\str)$ (podmínka stacionarity). Dále podmínka $\tagEq{4.2.4}$ se nazývá podmínka komplementarity a požadavek $y_1\str, \dots, y_k\str > 0$ jako podmínka duality.
Jistě $y_0 \str, y_1 \str, \dots, y_k \str \geq 0$, $y_{k+1} \str, \dots, y_m \str \in \R \iff y_0\str > 0$ a $y\str \in Q$
Jelikož situace s $y_0\str = 0$ je problematická, existují podmínky na zaručení $y_0\str \neq 0$, což je ekvivalentní s $y_0\str = 1$. Tyto podmínky se nazývají podmínky kvalifikovaného omezení:
- Regulárnost bodu $x\str$, tj, bod $x\str$ je regulární, pokud jsou $\grad g_i(x\str)$ pro $i \in S(x\str)$ lineárně nezávislé (tj. gradienty aktivních omezení jsou LNZ)
- afinní omezení - funkce $g_1, \dots, g_m$ jsou afinní
- Slaterova podmínka - $g_1, \dots, g_k$ jsou konvexní, $g_{k+1}, \dots, g_m$ jsou afinní, konstantní vektory $\grad g_i$ jsou lineárně nezávislé pro $i \in \set{k+1, \dots, m}$ a existuje $\bar x \in P$ takové, že $g_i(\bar x) < 0$ pro $i \in \set{1, \dots, k}$ a $g_j(\bar x) = 0$ pro $j \in \set{k+1, \dots, m}$
Důsledek $\D{4.2.2}$
Nechť $P \subseteq \R^n$ je konvexní množina, funkce $f, g_1, \dots, g_m$ jsou diferencovatelné na (nějaké otevřené množině obsahující) $P$ a pro $x\str \in X$ existují multiplikátory $y\str \in Q$ takové, že platí $\tagEq{4.2.3}$ & $\tagEq{4.2.4}$ s $y_0\str = 1$. Nechť je dále splněn (alespoň) jeden z následujících předpokladů:
- funkce $L(x, y\str)$ je konvexní na množině $P$
- úloha $\tagEq{4.1}$ & $\tagEq{4.2}$ je úlohou konvexního programování, tj. na konvexní množině $P$ jsou funkce $f, g_1, \dots, g_k$ konvexní a $g_{k+1}, \dots, g_m$ afinní
Pak bod $x\str$ je globálním řešením úlohy $\tagEq{4.1}$ & $\tagEq{4.2}$.
Teoreticky stačí pouze kvazikonvexní $g_1, \dots, g_k$
Věta $\D{4.2.3}$ (Karushova-Kuhnova-Tuckerova v diferenciálním tvaru)
Nechť $P \subseteq \R^n$ je konvexní množina, funkce $f, g_1, \dots, g_k$ konvexní a diferencovatelné na (nějaké otevřené množině obsahující) $P$, funkce $g_{k+1}, \dots, g_m$ afinní na $P$ a nechť platí (alespoň) jedna z následujících podmínek:
- (LNZ) množina $P$ je otevřená, vektory $\grad g_i(x), i \in S(x)$ jsou lineárně nezávislé pro každé $x \in X$.
- (Slaterova) funkcionální omezení jsou pouze tvaru nerovností, tj. $k = m$, a existuje bod $\bar x \in P$ takový, že $g_i(\bar x) < 0$ pro $i \in \set{1, \dots, k}$
- (lineární) množina $P$ je polyedr a funkce $g_1, \dots, g_k$ jsou afinní
Pak $x\str$ je řešením úlohy $\tagEq{4.1}$ & $\tagEq{4.2}$ právě tehdy, když existuje $y\str \in Q$ takové, že platí $\tagEq{4.2.3}$ & $\tagEq{4.2.4}$ s $y_0\str = 1$.
Věta $\D{4.2.4}$
Nechť funkce $f, g_1, \dots, g_m$ jsou dvakrát spojitě diferencovatelné v bodě $x\str$ a $x\str \in \interior P$ je takový, že existují multiplikátory $y\str \in Q$ splňující $\tagEq{4.2.3}$ & $\tagEq{4.2.4}$ s $y_0\str = 1$ a současně $y_i\str > 0$ pro $i \in I(x\str)$ (tzv. podmínka ostré komplementarity), tj. $$ \gradx L(x\str, y\str) = 0, $$ $$ g_i(x\str) \leq 0 \text{ pro } i \in \set{1, \dots, k}, \qquad g_i(x\str) = 0 \text{ pro } i \in \set{k+1, \dots, m}, $$ $$ y_i\str > 0 \text{ pro } i \in I(x\str), \qquad y_i\str = 0 \text{ pro } i \in \set{1, \dots, k} \setminus I(x\str), $$ $$ y_i\str \in \R \text{ pro } i \in \set{k+1, \dots, m} $$ Jestliže $$ \hessx L(x\str, y\str) > 0 \text{ na } \ker (\gradT g_i(x\str))_{i \in S(x\str)}, $$ tj. $h^T \hessx L(x\str, y\str) h > 0$ pro všechna $h \in \R^n \setminus \brackets{0}$ taková, že $\scal {\grad g_i(x\str)} h = 0$ pro $i \in S(x\str)$, pak bod $x\str$ je ostré lokální minimum funkce $f$ na množině $X$.
Duální úloha
$$ \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\norm#1{\left\lVert #1 \right\rVert} \xdef\dist{\rho} \xdef\and{\&}\xdef\brackets#1{\left\{ #1 \right\}} \xdef\parc#1#2{\frac {\partial #1}{\partial #2}} \xdef\mtr#1{\begin{pmatrix}#1\end{pmatrix}} \xdef\bm#1{\boldsymbol{#1}} \xdef\mcal#1{\mathcal{#1}} \xdef\vv#1{\mathbf{#1}}\xdef\vvp#1{\pmb{#1}} \xdef\ve{\varepsilon} \xdef\l{\lambda} \xdef\th{\vartheta} \xdef\a{\alpha} \xdef\vf{\varphi} \xdef\Tagged#1{(\text{#1})} \xdef\tagged*#1{\text{#1}} \xdef\tagEqHere#1#2{\href{#2\#eq-#1}{(\text{#1})}} \xdef\tagDeHere#1#2{\href{#2\#de-#1}{\text{#1}}} \xdef\tagEq#1{\href{\#eq-#1}{(\text{#1})}} \xdef\tagDe#1{\href{\#de-#1}{\text{#1}}} \xdef\T#1{\htmlId{eq-#1}{#1}} \xdef\D#1{\htmlId{de-#1}{\vv{#1}}} \xdef\conv#1{\mathrm{conv}\, #1} \xdef\cone#1{\mathrm{cone}\, #1} \xdef\aff#1{\mathrm{aff}\, #1} \xdef\lin#1{\mathrm{Lin}\, #1} \xdef\span#1{\mathrm{span}\, #1} \xdef\O{\mathcal O} \xdef\ri#1{\mathrm{ri}\, #1} \xdef\rd#1{\mathrm{r}\partial\, #1} \xdef\interior#1{\mathrm{int}\, #1} \xdef\proj{\Pi} \xdef\epi#1{\mathrm{epi}\, #1} \xdef\grad#1{\mathrm{grad}\, #1} \xdef\gradT#1{\mathrm{grad}^T #1} \xdef\gradx#1{\mathrm{grad}_x #1} \xdef\hess#1{\nabla^2\, #1} \xdef\hessx#1{\nabla^2_x #1} \xdef\subdif#1{\partial #1} \xdef\co#1{\mathrm{co}\, #1} \xdef\iter#1{^{[#1]}} \xdef\str{^*} \xdef\spv{\mcal V} \xdef\civ{\mcal U} \xdef\knvxProg{\tagEqHere{4.1}{./nutne-a-postacujici-podminky-optimality} \, \and \, \tagEqHere{4.2}{nutne-a-postacujici-podminky-optimality}} $$
Definice $\D{4.3.1}$ (Kuhnovy-Tuckerovy vektory)
Vektor $y\str \in Q$ (prvních $k$ složek je nezáporných) se nazývá Kuhnnovým-Tuckerovým vektorem (K-T vektorem) úlohy $\knvxProg$, jestliže $$ f\str \leq f(x) + \sum_{i = 1}^m y_i\str g_i(x) = L(x,y\str) \quad \forall x\in P, \tag{\T{4.3.0}} $$ kde $f\str := \inf_{x \in X} f(x)$ je hodnota úlohy $\knvxProg$.
K-T vektor pro danou úlohu nemusí existovat
Věta $\D{4.3.2}$
Nechť úloha $\knvxProg$ je úlohou konvexního programování, tj. množina $P \subseteq \R^n$ je konvexní, funkce $f, g_1, \dots, g_k$ konvexní a $g_{k+1}, \dots, g_m$ jsou afinní, a nechť dále platí (alespoň) jedna z podmínek regularity:
- (Slaterova) $k = m$ a existuje $\bar x \in P$ takové, že $g_i(\bar x) < 0$ pro $i = 1, \dots, m$
- (lineární) množina $P$ je polyedr, funkce $f, g_1, \dots, g_k$ jsou afinní a $X \neq \emptyset$.
Pak existuje K-T vektor úlohy $\knvxProg$.
Zde se podmínka 2. liší od podmínky 3. ve Větě $\tagDeHere{4.2.3}{./nutne-a-postacujici-podminky-optimality}$ - vyžaduje ještě neprázdnost přípustné množiny
Úloha konvexního programování splňující nějakou z podmínek z Věty $\tagDe{4.3.2}$ se nazývá regulární.
Definice $\D{4.3.3}$ (Duální úloha)
Nechť $y \in Q$. Definujme funkci $$ \vf(y) := \inf_{x \in P} L(x,y) = \inf_{x \in P} \left( f(x) + \sum_{i = 1}^m y_i g_i(x) \right) $$ a množinu (tzv. efektivní definiční obor) $$ Y := \set{y \in Q \mid \vf(y) > -\infty}. $$ Pak úloha $$ \vf(y) \to \max, \qquad y \in Y \tag{\T{4.3.1}} $$ se nazývá duální úlohou k úloze $\knvxProg$. Číslo $$ \vf\str := \sup_{y \in Y} \vf(y) $$ se nazývá hodnotou duální úlohy $\tagEq{4.3.1}$.
Úloha $\tagEq{4.3.1}$ je úlohou konkávního programování, tj. množina $Y$ je konvexní a funkce $\vf$ je konkávní na $Y$.
Věta $\D{4.3.5}$ (Slabá věta o dualitě)
Pro každé $x \in X$ a každé $y \in Q$ platí $$ f(x) \geq \vf(y) $$ Zejména, pokud $X \neq \emptyset$ a $Y \neq \emptyset$, pak $f\str \geq \vf\str$.
V případě $X = \emptyset$ a/nebo $Y = \emptyset$ je nerovnost splněna triviálně, neboť $\inf \emptyset = \infty$ a $\sup \emptyset = - \infty$.
Věta $\tagDe{4.3.5}$ říká, že pro duální rozdíl $g$ (duality gap) s $x \in X \neq \emptyset$ a $y \in Y \neq \emptyset$ bude platit $$ g(x,y) := f(x) - \vf(y) \geq 0 $$ Navíc číslo $g(x\str,y\str) := f\str - g\str$ udává tzv. optimální duální rozdíl (optimal duality gap). Dá se také říct, že pro libovolné $y \in Q$ je hodnota $\vf(y)$ dolní hranicí minima účelové funkce úlohy $\knvxProg$.
Certifikát optimality
Jsou-li $x\str \in X$ a $y\str \in Q$ taková, že platí $$ f(x\str) = \vf(y\str), $$ pak $x\str$ a $y\str$ jsou optimálními řešeními svých příslušných úloh.
Duální rozdíl je úzce spjat s existencí K-T vektorů. Jestliže je duální rozdíl nenunlový, tj. $f\str > \vf\str$, pak množina K-T vektorů musí být prázdná.
Jinak řečeno, existence K-T vektorů zaručuje $f\str = \vf\str$
Věta $\D{4.3.6}$ (Silná věta o dualitě)
Nechť úloha $\knvxProg$ je regulární úlohou konvexního programování (viz. Věta $\tagDe{4.3.2}$). Pokud $f\str > -\infty$, pak platí tzv. vztah duality $$ f\str = \vf\str, \quad \text{ tj. } \quad \inf_{x \in P}\sup_{y \in Q}L(x,y) = \sup_{y \in Q}\inf_{x \in P} L(x,y), $$ přičemž množina řešení duální úlohy $\tagEq{4.3.1}$ je neprázdná a shodná s množinou všech K-T vektorů úlohy $\knvxProg$.
Z Věty $\tagDe{4.3.6}$ vyplývá, že pokud $\knvxProg$ je regulární úlohou konvexního programování (viz Věta $\tagDe{4.3.2}$) a
- jestliže $Y \neq \emptyset$, pak duální úloha je řešitelná a $f\str > -\infty$
- jestliže $Y = \emptyset$, pak $f\str = -\infty$
Celkem z Vět $\tagDe{4.3.5}, \tagDe{4.3.6}$ a z bezprostředně výše uvedného důsledku vyplývá, že v případě regulární úlohy konvexního programování mohou nastat pouze 2 možnosti
| Duální Ú. \ Primární Ú. | Nepřípustná ($f\str = \infty$) | Přípustná a Omezená | Neomezená ($f\str = -\infty$) |
|---|---|---|---|
| Neomezená ($\vf\str = \infty$) | NE (Ano bez regularity) | NE | NE |
| Přípustná a Omezená | NE (Možná bez regularity) | ANO | NE |
| Nepřípustná ($\vf\str = -\infty$) | NE (Ano bez regularity) | NE | ANO |
Z regularity plyne, že $X \neq \emptyset$
Věta $\D{4.3.8}$ (Kuhnova-Tuckerova v nediferenciálním tvaru)
Nechť úloha $\knvxProg$ je regulární úlohou konvexního programování (viz Věta $\tagDe{4.3.2}$). Pak $x\str \in X$ je řešením této úlohy právě tehdy, když platí (alespoň) jedna z podmínek:
- existuje $y\str \in Q$ takové, že $f(x\str) = \vf(y\str)$
- existuje $y\str \in Q$ takové, že
$$L(x\str,y\str) = \min_{x \in P}L(x, y\str), \tag{\T{4.3.2}}$$ $$y_i\str g_i(x\str) = 0, \quad i \in \set{1, \dots, m}, \tag{\T{4.3.3}}$$ Navíc množina takovýchto vektorů $y\str \in Q$ splývá s množinou řešení duální úlohy (a podle Věty $\tagDe{4.3.6}$ tedy i s množinou K-T vektorů úlohy $\knvxProg$).
Jsou-li navíc funkce $f, g_1, \dots, g_m$ diferencovatelné v bodě $x\str$, pak podmínka $\tagEq{4.3.2}$ je ekvivalentní s podmínkou $\tagEqHere{4.2.3}{./nutne-a-postacujici-podminky-optimality}$ pro $y_0\str = 1$, zatímco $\tagEq{4.3.3}$ odpovídá $\tagEqHere{4.2.4}{./nutne-a-postacujici-podminky-optimality}$.
Tedy Věta $\tagDe{4.3.8}$ je skutečně zobecnění KKT Věty $\tagDeHere{4.2.3}{./nutne-a-postacujici-podminky-optimality}$ pro případ nediferencovatelných funkcí
Také se dá říct, že koncept K-T vektorů je zobecněním Lagrangeových multiplikátorů s kvalifikovanými omezeními (kvůli $y_0\str = 1$) - K-T vektory splývají s multiplikátory za podmínek Věty $\tagDeHere{4.2.3}{./nutne-a-postacujici-podminky-optimality}$
Definice $\D{4.3.9}$ (Sedlový bod)
Bod $[x\str, y\str] \in P \times Q$ se nazývá sedlovým bodem Lagrangeovy funkce $L(x,y)$ úlohy $\knvxProg$ na $P \times Q$, jestliže $$ L(x\str,y) \leq L(x\str, y\str) \leq L(x,y\str) \quad \forall x \in P, y \in Q, $$ tj. platí $$ L(x\str,y\str) = \max_{y \in Q} L(x\str, y) = \min_{x \in P} L(x,y\str) $$
Věta $\D{4.3.10}$ (Kuhnova-Tuckerova pro sedlový bod)
Nechť úloha $\knvxProg$ je regulární úlohou konvexní programování (viz Věta $\tagDe{4.3.2}$). Pak bod $x\str \in P$ je řešením úlohy $\knvxProg$ právě tehdy, když existuje $y\str \in Q$ takové, že $[x\str, y\str]$ je sedlovým bodem Lagrangeovy funkce $L(x,y)$ úlohy $\knvxProg$ na $P \times Q$.
Analýza citlivosti
$$ \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\norm#1{\left\lVert #1 \right\rVert} \xdef\dist{\rho} \xdef\and{\&}\xdef\brackets#1{\left\{ #1 \right\}} \xdef\parc#1#2{\frac {\partial #1}{\partial #2}} \xdef\mtr#1{\begin{pmatrix}#1\end{pmatrix}} \xdef\bm#1{\boldsymbol{#1}} \xdef\mcal#1{\mathcal{#1}} \xdef\vv#1{\mathbf{#1}}\xdef\vvp#1{\pmb{#1}} \xdef\ve{\varepsilon} \xdef\l{\lambda} \xdef\th{\vartheta} \xdef\a{\alpha} \xdef\vf{\varphi} \xdef\Tagged#1{(\text{#1})} \xdef\tagged*#1{\text{#1}} \xdef\tagEqHere#1#2{\href{#2\#eq-#1}{(\text{#1})}} \xdef\tagDeHere#1#2{\href{#2\#de-#1}{\text{#1}}} \xdef\tagEq#1{\href{\#eq-#1}{(\text{#1})}} \xdef\tagDe#1{\href{\#de-#1}{\text{#1}}} \xdef\T#1{\htmlId{eq-#1}{#1}} \xdef\D#1{\htmlId{de-#1}{\vv{#1}}} \xdef\conv#1{\mathrm{conv}\, #1} \xdef\cone#1{\mathrm{cone}\, #1} \xdef\aff#1{\mathrm{aff}\, #1} \xdef\lin#1{\mathrm{Lin}\, #1} \xdef\span#1{\mathrm{span}\, #1} \xdef\O{\mathcal O} \xdef\ri#1{\mathrm{ri}\, #1} \xdef\rd#1{\mathrm{r}\partial\, #1} \xdef\interior#1{\mathrm{int}\, #1} \xdef\proj{\Pi} \xdef\epi#1{\mathrm{epi}\, #1} \xdef\grad#1{\mathrm{grad}\, #1} \xdef\gradT#1{\mathrm{grad}^T #1} \xdef\gradx#1{\mathrm{grad}_x #1} \xdef\hess#1{\nabla^2\, #1} \xdef\hessx#1{\nabla^2_x #1} \xdef\jacobx#1{D_x #1} \xdef\jacob#1{D #1} \xdef\subdif#1{\partial #1} \xdef\co#1{\mathrm{co}\, #1} \xdef\iter#1{^{[#1]}} \xdef\str{^*} \xdef\spv{\mcal V} \xdef\civ{\mcal U} \xdef\knvxProg{\tagEqHere{4.1}{./nutne-a-postacujici-podminky-optimality} \, \and \, \tagEqHere{4.2}{nutne-a-postacujici-podminky-optimality}} $$
Nyní se budeme věnovat řešení úlohy matematické programování v závislosti na parametru.
První se podíváme na úlohu matematické programování s omezeními pouze ve tvaru rovností, ale s obecnou závislostí na parametrech.
A v druhém (a posledním) případě se podíváme na úlohu s omezeními ve tvaru nerovností, ale s parametry pouze v podobě absolutních členů ve funkcích zadávajících tyto omezení.
Zde je dobré podotknout, že druhý případ je mírně užitečnější a navíc si uvědomme, že 1 rovnost lze napsat jako 2 nerovnosti
Úlohy s rovnostmi
Věta $\D{4.4.1}$ (O obálce)
Mějme úlohu $$ f(x,r) \to \min, \qquad g_1(x, r) = 0, \; \dots, \; g_m(x,r) = 0 \tag{\T{AC.1}} $$ kde $x \in \R^n, r \in \R^k, f, g_1, \dots, g_m \in C^1$. Připusťme, že pro každou hodnotu parametru $r$ má úloha $\tagEq{AC.1}$ jediné řešení, které označíme $x\str (r)$. Potom hodnota úlohy $\tagEq{AC.1}$ je $$ f\str(r) = f(x\str(r), r). $$ Je-li $x\str(r)$ diferencovatelná vzhledem k $r$ a Jacobiho matice $\jacobx G(x\str (r), r) \in \R^{m\times n}$ má plnou hodnost $m$, pak platí $$ \parc {} {r_i}f\str(r) = \parc f {r_i} (x\str(r), r) + \sum_{j = 1}^m y_j\str(r) \parc {g_j} {r_i} (x\str(r), r) $$
Obálka je křivka, která se množiny křivek dotýká (tj. se dotýká každé křívky) a má společnou tečnu s danou křivkou
Jinak řečeno je tečná k množině křivek

Požadavky Věty $\tagDe{4.4.1}$ jsou relativně silné, proto uveďme její "slabší verzi".
Věta $\D{4.4.2}$
Nechť $f, g_1, \dots, g_m \in C^2$ a $x\str$ je lokálním řešením úlohy $$ f(x) \to \min, \qquad g_1(x) = 0, \dots, g_m(x) = 0 $$ s odpovídajícími Lagrangeovými multiplikátory $y\str$. Nechť dále tato dvojice splňuje postačující podmínku druhého řádu, tj. $\hessx L(x\str, y\str) > 0$ na $\ker \jacob G(x\str)$, přičemž současně $x\str$ je regulárním bodem, tj. $\jacobx G(x\str) \in \R^{m\times n}$ má plnou hodnost $m$. Uvažme úlohu parametrického programování $$ f(x) \to \min, \qquad G(x) = u \tag{\T{AC.2}}, $$ pro parametr $u \in \R^m$. Pak existuje otevřená koule $S$ se středem v počátku ($u = 0$) taková, že pro každé $u \in S$ existuje lokální řešení $x\str(u) \in \R^n$ úlohy $\tagEq{AC.2}$ a odpovídající $y\str(u) \in \R^m$. Navíc $x\str(\cdot)$ a $y\str(\cdot)$ jsou spojitě diferencovatelné funkce na $S$ a platí $x\str(0) = x\str, y\str(0) = y\str$ a pro každé $u \in S$ máme $$ \grad f\str(u) = - y\str(u), $$ kde $f\str(u)$ značí optimální hodnotu úlohy $\tagEq{AC.2}$ vzhledem k $u$, tj. klademe $f\str(u) := f(x\str(u))$.
Jednoduše řečeno se optimální hodnota mění podle Lagrangeových multiplikátorů pro danou hodnotu $u$
Úlohy s nerovnostmi
Uvažujme úlohu závislou na $m$-tici parametrů $b = (b_1, \dots, b_m)^T \in \R^m$, tj. $$ f(x) \to \min, \qquad x \in X(b) := \set{x \in P \subseteq \R^n \mid g_i(x) \leq b_i, \; i \in \set{1, \dots, m}} \tag{\T{4.4.2}} $$ A dále zaveďme značení $$ G(x) := (g_1(x), \dots, g_m(x))^T, \quad X(b) := \set{x \in P \mid G(x) \leq b} $$ $$ B := \set{b \in \R^m \mid X(b) \neq \emptyset}, \quad F(b) := \inf_{x \in X(b)} f(x), \; b \in B $$ množinu K-T vektorů úlohy $\tagEq{4.4.2}$ označme $$ Y(b) := \set{y \in \R^m \mid y \geq 0, \; F(b) \leq f(x) + \scal{y} {G(x) - b} \; \forall x \in P} $$ a subdifereniál funkce $F(b)$ (viz Definice $\tagDeHere{2.5.1}{./subgradient-a-subdiferencial-a-fenchelova-transformace}$) označme $$ \subdif F(b) := \set{a \in \R^m \mid F(b') - F(b) \geq \scal a {b' - b} \; \forall b' \in B} $$
Věta $\D{4.4.3}$
Nechť množina $P \subseteq \R^n$ je konvexní, funkce $f, g_1, \dots, g_m$ jsou konvexní na $P$ a platí $0 \in B, F(0) > -\infty$ a $Y(0) \neq \emptyset$. Potom
- množina $B$ je konvexní
- funkce $F(b)$ je konečná, konvexní a nerostoucí na $B$
- platí $\subdif F(b) = -Y(b)$ pro všechna $b \in B$
Z předpokladů Věty $\tagDe{4.4.3}$ plyne, že
- úloha $\tagEq{4.4.2}$ je přípustná pro $b = 0$
- úloha $\tagEq{4.4.2}$ má řešení pro $b = 0$
- množina K-T vektorů úlohy $\tagEq{4.4.2}$ je neprázdná (toto není splněno automaticky, viz Věta $\tagDeHere{4.3.2}{./dualni-uloha}$)
Navíc je-li $F$ dokonce diferencovatelná v $b$, pak $\subdif F(b)$ je jednoprvková množina, která obsahuje pouze $-\gradT F(b)$ a tedy tento vektor musí být roven $(-1) \cdot$ jediný K-T vektor této úlohy. (Toto je analogie Věty O obálce $\tagDe{4.4.1}$)
Podle Věty $\tagDeHere{4.3.6}{./dualni-uloha}$ jsme popsali K-T vektory úlohy $\knvxProg$ pomocí řešení duální úlohy $\tagEqHere{4.3.1}{./dualni-uloha}$. Část 3. této věty jim navíc dává ještě charaketeristiku subgradientu hodnoty úlohy parametrického programování $\tagEq{4.4.2}$.
V případě regulární úlohy konvexního programování dostáváme zkombinováním těchto dvou výsledků $\subdif F(b) = - Y\str(b)$, kde $Y\str(b)$ je množina řešení duální úlohy (viz Věta $\tagDeHere{4.3.6}{./dualni-uloha}$).
Pomocí Věty $\tagDe{4.4.3}$ jsme schopni dostat zajímavé výsledky o původní úloze matematického programování, tj. $\tagEq{4.4.2}$ s $b = 0$.
Důsledek $\D{4.4.4}$
Nechť množina $P \subseteq \R^n$ je konvexní, funkce $f, g_1, \dots, g_m$ jsou konvexní na $P$, platí $F(0) > - \infty$ a existuje $\bar x \in P$ takové, že $G(\bar x) < 0$ (viz Slaterova podmínka ve Větě $\tagDeHere{4.3.2}{./dualni-uloha}$). Potom $0 \in B$ a
- funkce $F(\cdot)$ je spojitá v bodě $b = 0$
- pro libovolné $h \in \R^m$ existuje jednostranná směrová derivace
$$F'_ h(0) = \max_ {y\str \in Y(0)} \scal {-y\str} h$$ - funkce $F$ je diferencovatelná v bodě $b = 0$ právě tehdy, když $Y(0)$ je jednoprvková množina, tj. $Y(0) = \brackets{y\str}$. Navíc platí $\gradT F(0) = -y\str$.
Z části 3. okamžitě plyne, že pokud existuje více K-T vektorů $\iff$ funkce $F$ není diferencovatelná
Fenchelova transformace a duální úloha
Lze ukázat, že pro $F(b)$ hodnotu primární úlohy je $F\str(y) = -\vf(y)$ a tedy duální úlohu $\tagEqHere{4.3.1}{./dualni-uloha}$ je možné psát jako $$ -F\str(y) \to \max, \quad y \geq 0 $$
M5120 Lineární statistické modely
2. cvičení
$$ \xdef\mcal#1{\mathcal{#1}} \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\N{\mathbb N} \xdef\R{\mathbb R} \xdef\Q{\mathbb{Q}} \xdef\Z{\mathbb{Z}} \xdef\D{\mathbb{D}} \xdef\bm#1{\boldsymbol{#1}} \xdef\vv#1{\mathbf{#1}} \xdef\vvp#1{\pmb{#1}} \xdef\floor#1{\lfloor #1 \rfloor} \xdef\ceil#1{\lceil #1 \rceil} \xdef\grad#1{\mathrm{grad} , #1} \xdef\ve{\varepsilon} $$
Lineární model
Obecně má tvar $$ Y_i = \beta_0 + \beta_1 x_{i, 1} + \dots + \beta_k x_{i, k} + \ve_i, $$ kde $i = 1, \dots, n$. $Y_i$ je naše "cílová proměnná" (regresand). Proměnné $x_{i,1}, \dots, x_{i,k}$ jsou kovariáty (regresor, prediktor) a jsou pevně dané. Dále máme regresní koeficienty $\beta_0, \dots, \beta_k$ a $\varepsilon_i$ je náhodná proměnná chyby.
Také platí $$ \varepsilon_i \sim^{iid} (0, \sigma^2) $$ $$ E(\varepsilon_i) = 0 $$ $$ var(\varepsilon_i) = \sigma^2 $$ $$ cov(\varepsilon_i) = 0 $$
Celkem máme $$ \begin{pmatrix} Y_1 \ Y_2 \ \vdots \ Y_n \end{pmatrix} = \begin{pmatrix} 1 & x_{1,1} & \dots & x_{1, k} \ 1 & x_{2,1} & \dots & x_{2, k} \ \vdots & \vdots & \ddots & \vdots\ 1 & x_{n,1} & \dots & x_{n, k} \ \end{pmatrix} \cdot \begin{pmatrix} \beta_0 \ \beta_1 \ \vdots \ \beta_k \end{pmatrix} + \begin{pmatrix} \varepsilon_1 \ \varepsilon_2 \ \vdots \ \varepsilon_n \end{pmatrix} \tag{LSM} $$ A vektorově $$ \vv{Y} = \underbrace{\vv{X}}_{\text{matice plánu}} \cdot \vvp{\beta} + \vvp{\varepsilon} $$
Tedy pro 2. cvičení
02 / a)
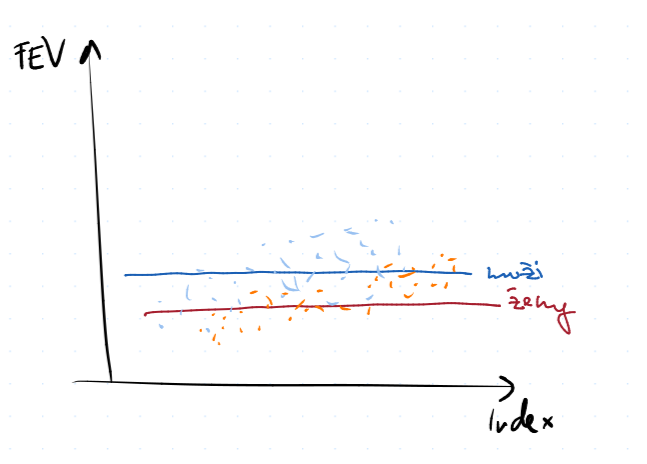
$$FEV_i = \beta_0 + \ve_i$$
Můžeme si představit jako funkci $y = \beta_0$
A matice plánu bude
$$
\begin{pmatrix}
1 \
1 \
\vdots \
1
\end{pmatrix}
$$
Tedy kapacita plic je podle tohoto modelu konstantní a vizuálně znázorněné jako
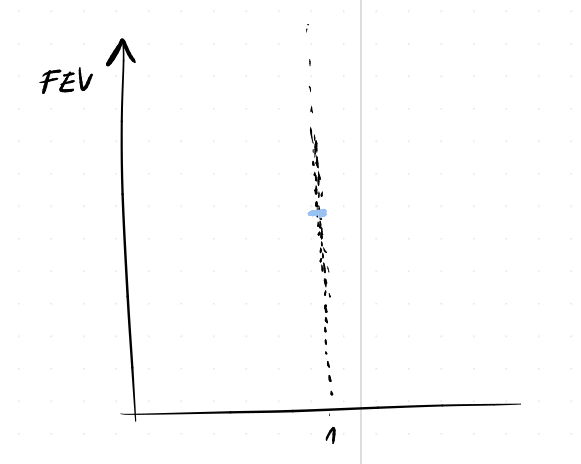
02 / c)
$$ FEV_i = \beta_0 + \beta_1 \cdot \text{Height}_i + \ve_i $$
Kapacitu plic modelujeme pomocí výšky. Tedy v tomto případě chceme funkci $y = \beta_0 + \beta_1 x$.
A graficky
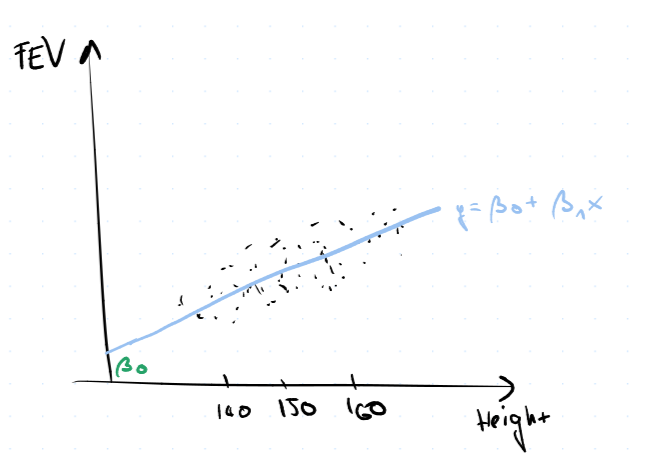
A matice plánu tentokrát bude $$ \begin{pmatrix} 1 & \text{Height}_1 \ 1 & \text{Height}_2 \ \vdots \ 1 & \text{Height}_n \end{pmatrix}, $$ což dosazujeme do $(LSM)$.
Tedy máme model hledáme $y = \beta_0 + \beta_1 x$ a zde
- $\beta_0$ ... střední hodnota predikce při nulových hodnotách ostatních prediktorů
- $\beta_1$ ... nárůst střední hodnoty predikce při nárůstu výšky (prediktor $\text{Height}$) o 1 cm
02 / b)
$$ FEV_i = \beta_0 + \beta_1 \cdot \text{Sex}_i + \ve_i $$
a $\beta_1$ zde reprezentuje rozdíl predikce mezi muži a ženami s maticí plánu $$ \begin{pmatrix} 1 & 1 \ 1 & 0 \ \vdots \ 1 & 1 \end{pmatrix}, $$
kde $1$ reprezentuje muže.
A graficky
02/ d)
$$ FEV_i = \beta_0 + \beta_1 \cdot \text{Height}_i + \beta_2 \text{Height}_i^2 + \ve_i $$ V tomto případě je $\beta_1, \beta_2$ jsou složité na interpretaci
A matice plánu by v tomto případě byla $$ \begin{pmatrix} 1 & \text{Height}_1 & \text{Height}^2_1 \ 1 & \text{Height}_2 & \text{Height}^2_2 \ \vdots \ 1 & \text{Height}_n & \text{Height}^2_n \end{pmatrix}, $$
02 / e)
$$ FEV_i = \beta_0 + \beta_1 \cdot \text{Height}_i + \beta_2 \text{Sex}_i + \ve_i $$ s maticí plánu $$ \begin{pmatrix} 1 & \text{Height}_1 & 0 \ 1 & \text{Height}_2 & 1 \ \vdots \ 1 & \text{Height}_n & 1 \end{pmatrix}, $$ přičemž ve 3. sloupci jsou $1$ značí muže.
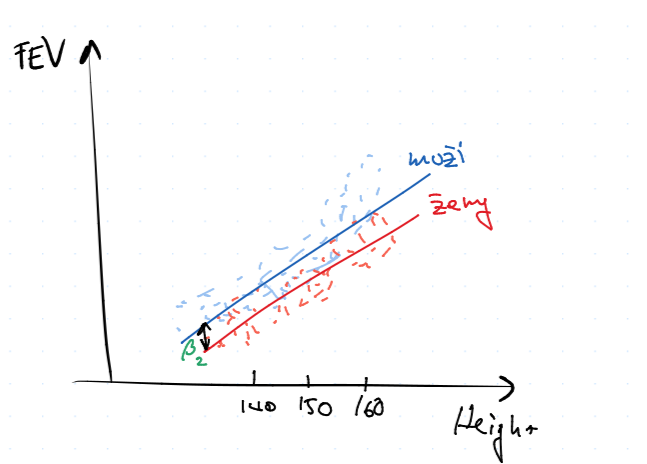
A hledáme přímku $$ y = \beta_0 + \beta_1 x + \beta_2 \vv I \set{\text{Sex} = \text{"male"}} $$
s významem koeficientů
- $\beta_0$ ... střední hodnota predikce při nulových hodnotách ostatních prediktorů (nulová výška a ženské pohlaví)
- $\beta_1$ ... změna střední hodnoty predikce při nárůstu výšky (prediktor $\text{Height}$) o 1 cm pro ženy
- $\beta_2$ ... rozdíl střední hodnoty predikce mezi muži a ženami
02 / g)
$$ FEV_i = \beta_0 + \beta_1 \cdot \text{Height}_i + \beta_2 \text{Sex}_i + \beta_3 (\text{Sex}_i \times \text{Height}_i) + \ve_i, $$ kde členu $\text{Sex}_i \times \text{Height}_i$ interakce a matice plánu bude $$ \begin{pmatrix} 1 & \text{Height}_1 & 0 & 0 \ 1 & \text{Height}_2 & 1 & \text{Height}_2 \ 1 & \text{Height}_3 & 0 & 0 \ \vdots & \vdots & \vdots & \vdots \ 1 & \text{Height}_n & 1 & \text{Height}_n \end{pmatrix}, $$ přičemž ve 3. sloupci jsou $1$ značí muže.
A hledáme přímku $$ y = \beta_0 + \beta_1 x + \beta_2 \vv I \set{\text{Sex} = \text{"male"}} + \beta_3 x \vv I \set{\text{Sex} = \text{"male"}}, $$ tj.
- žena ... $y = \beta_0 + \beta_1 x$
- muž ... $y = (\beta_0 + \beta_2) + (\beta_1 + \beta_3)x$
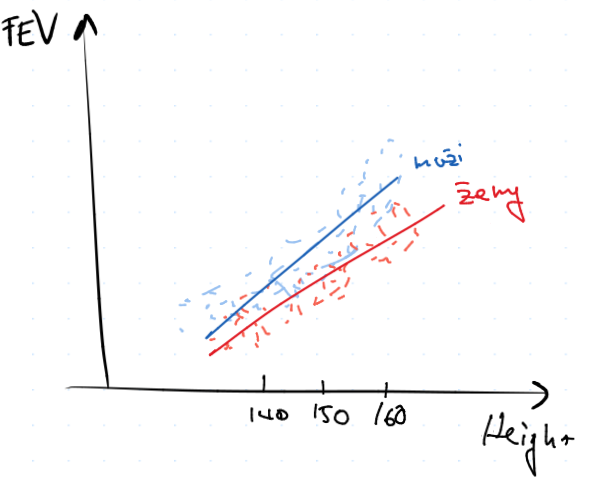
Zde $\beta_3$ značí rozdíl střední hodnoty predikce mezi muži a ženami při nárůstu výšky o 1 cm
rozdíl rychlosti růstu $\text{FEV}$ mezi muži a ženami

3. cvičení
$$ \xdef\mcal#1{\mathcal{#1}} \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\N{\mathbb N} \xdef\R{\mathbb R} \xdef\Q{\mathbb{Q}} \xdef\Z{\mathbb{Z}} \xdef\D{\mathbb{D}} \xdef\bm#1{\boldsymbol{#1}} \xdef\vv#1{\mathbf{#1}} \xdef\vvp#1{\pmb{#1}} \xdef\floor#1{\lfloor #1 \rfloor} \xdef\ceil#1{\lceil #1 \rceil} \xdef\grad#1{\mathrm{grad} , #1} \xdef\ve{\varepsilon} $$
Příklad 1
Máme symetrickou, pozitivně definitní matici $m \times m$ značenou $\Sigma$.
a)
Poz. def $\iff$ všechna vlastní čísla jsou kladná $\implies$ $\det(\lambda_1 \dots \lambda_m) > 0$ $\implies$ inverze bude existovat $\implies h(\Sigma) = m$
b)
Matice $\Sigma$ je samoadjungovaný operátor Inverzi sestrojíme pomocí spektrálního rozkladu. $$ \Sigma = U \Lambda U^T, $$ kde $U$ je tvořená vlastními vektory a je ortogonální ($U \cdot U^T = I$) a $\Lambda$ je diagonální matice vlastních čísel.
Pak inverze je $$ \Sigma^{-1} = U \Lambda^{-1} U^T $$
A jako ověření $$ \Sigma \Sigma^{-1} = U \Lambda U^T U \Lambda^{-1} U^T = I $$
c)
Ze spektrálního rozkladu je jistě matice $\Sigma^{-1}$ pozitivně definitní. Nechť $\vv x \neq 0$ libovolné, pak $$ \vv x^T \Sigma^{-1} \vv x = \vv x^T U \Lambda^{-1} U^T \vv x = \vv x^T U \Lambda^{-\frac 1 2} \Lambda^{-\frac 1 2} U^T \vv x, $$ kde $\Lambda^{-\frac 1 2}$ je matice s převrácenými hodnotami odmocnin vlastních čísel matice $\Sigma$ na diagonále a tedy $$ \underbrace{\vv x^T U \Lambda^{-\frac 1 2}}{\vv y} \underbrace{\Lambda^{-\frac 1 2} U^T \vv x}{\vv y^T} = \vert \vert \vv y \vert \vert^2 > 0 $$
d)
Mějme množinu $S_c$ takovou, že $$ S_c = {\vv x; ; (\vv x - \vv \mu)^T \Sigma^{-1} (\vv x- \vv \mu) = c }, $$ kde $\vv \mu \in \R^m$ a $c \in \R$.
Pro $c < 0$ je $S_c \equiv \emptyset$.
Dále pro $c = 0$ je řešením pouze $S_c = {\vv \mu}$.
Nakonce pro $c > 0$ je
$$
\underbrace{(\vv x - \vv \mu)^T U}_{\vv y} \Lambda^{-1} U^T (\vv x - \vv \mu) = \vv y^T \Lambda^{-1} \vv y
$$
A pro $m = 2$ tedy
$$
(y_1 ; y_2)
\begin{pmatrix}
\frac 1 {\lambda_1} & 0 \
0 & \frac 1 {\lambda_2}
\end{pmatrix}
\begin{pmatrix}
y_1 \ y_2
\end{pmatrix} = c
$$
$$
\frac {y_1^2} {\lambda_1} + \frac{y_2^2} {\lambda_2} = c,
$$
což je rovnice elipsy se středem $(\mu_1, \mu_2)$ a směry os jsou právě vlastní vektory $\Sigma$. Nakonec délky poloos budou $\sqrt{c \lambda_i}$
Analogicky pro $m > 2$ dostaneme elipsoid.
Příklad 4
Matice $\Sigma$ je poz. semidef matice symetrická matice $m \times m$.
a)
$$ h(\Sigma) = r, $$ kde $0 < r \leq m$.
Nahradíme $U$ za matici $$ U_1 = \begin{pmatrix} \vv u_1 & \vert & \vv u_2 & \vert & \dots & \vert & \vv u_r \end{pmatrix} $$ a také $$ \Lambda_1 = \mathrm{diag} (\lambda_1, \dots, \lambda_r) $$
b)
Sestrojme matici $\tilde{\Sigma}$ takovou, že $\tilde{\Sigma} \tilde{\Sigma}^T = \Sigma$ jako $$ \tilde{\Sigma} = U_1 \Lambda_1^{\frac 1 2}, $$ když je $h(\Sigma) = r$ a pro $h(\Sigma) = m$ jako $\tilde{\Sigma} = U \Lambda^{\frac 1 2}$.
d)
Zde značím pseudoinverzi matice $A$ jako $A^\dagger$
$\tilde{\Sigma}^\dagger = \Lambda_1^{- \frac 1 2} U_1^T$ a pro tuto matici bychom ukázali všechny 4 vlastnosti pseudoinverze, tj.
- $A A^\dagger A = A$
- $A^\dagger A A^\dagger = A^\dagger$
- $(A^\dagger A)^T = A^\dagger A$
- $(A A^\dagger)^T = A A^\dagger$
4. cvičení
$$ \xdef\mcal#1{\mathcal{#1}} \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\N{\mathbb N} \xdef\R{\mathbb R} \xdef\Q{\mathbb{Q}} \xdef\Z{\mathbb{Z}} \xdef\D{\mathbb{D}} \xdef\bm#1{\boldsymbol{#1}} \xdef\vv#1{\mathbf{#1}} \xdef\vvp#1{\pmb{#1}} \xdef\floor#1{\lfloor #1 \rfloor} \xdef\ceil#1{\lceil #1 \rceil} \xdef\grad#1{\mathrm{grad} , #1} \xdef\ve{\varepsilon} \xdef\im#1{\mathrm{im}(#1)} \xdef\tr#1{\mathrm{tr}(#1)} \xdef\norm#1{\left\vert \left\vert #1 \right\vert\right\vert} \xdef\scal#1#2{\langle #1, #2 \rangle} $$
1. příklad
Máme symetrickou idempotentní matice $P$ velikosti $n\times n$, což je matice ortogonální projekce.
a)
Jelikož je $P$ symetrická, tak existuje spektrální rozklad tvaru $$ P = U \Lambda U^T $$
matice $U$ je ortogonální a plné hodnosti
a jelikož je idempotentní $$ P = PP $$ Potom $$ U\Lambda U^T = P = PP = U \Lambda \underbrace{U^T U}_{I} \Lambda U^T = U \Lambda^2 U^T $$ A celkem dostáváme $\Lambda^2 = \Lambda$. Navíc jelikož je $\Lambda$ diagonální, tak pro všechna vlastní čísla $\lambda$ matice $\Lambda$ platí $$ \lambda^2 = \lambda\ (\lambda - 1)\lambda = 0 \implies \lambda = 0 \lor \lambda = 1 $$
Idempotentní matice $P$ je invertibilní právě tehdy, když $P = I$
b)
Jelikož $P = U\Lambda U^T$, pak $U$ je plné hodnosti (je ortogonální), pak $$ h(P) = h(U\Lambda U^T) = h(\Lambda) = | \set{\lambda_i, \; \lambda_i = 1} | $$
c)
Z části b) máme $$ \implies h(P) = \dots = \sum \lambda_i = \tr \Lambda = \tr {\Lambda U U^T} $$ A jelikož pro stopu součinu matic platí $\tr {A B C} = \tr {C A B}$ (invariantnost vůči cyklickým operacím), pak $$ \implies h(P) = \dots = \tr {U \Lambda U^T} = \tr P $$
d)
Je-li vektor $\vv y \in \im P$, pak $P \vv y = \vv y$ Pokud $\vv y \in \im P$, pak $\exists \vv z$, že $\vv y = P \vv z$
Definice obrazu $\im P$: $$\im P = \set{\vv y \in \R^n \mid \exists \vv z \in \R^n : \; P\vv z = \vv y}$$
Pak $$ P \vv y = P (P \vv z) = (P P) \vv z = P \vv z = \vv y $$
e)
Chceme ukázat, že projekce do menšího podprostoru je zároveň projekce do onoho většího prostoru
Nechť $\vv z \in \R^n$ je libovolné, projekce $z$ do menšího prostoru je prvek většího prostoru. $$ \tilde P \vv z \in \im {\tilde P} \leq \im P $$ Pak podle d) platí $$ P(\tilde P \vv z) = \tilde P \vv z\ P(\tilde P \vv z) - \tilde P \vv z = \vv 0 \ (P\tilde P - \tilde P) \vv z = \vv 0, $$ nicméně vektor $\vv z$ byl libovolný. To tedy znamená, že zobrazení $P \tilde P - \tilde P$ pošle všechny $\vv z \in \R^n$ na nulový vektor, tj. $$ \ker (P \tilde P - \tilde P) = \R^n $$ Z lineární algebry víme, že $\dim \ker(A) + \dim \im A = n$ pro $A$ tvaru $n \times n$. A tedy $$ \dim \im {P \tilde P - \tilde P} = 0 \implies P \tilde P - \tilde P = \vv 0 $$ Neboť $P, \tilde P$ jsou ortogonální projekce, tak jsou symetrické. Celkem $$ \tilde P P = \tilde P^T P^T = (\tilde P P)^T = \tilde P^T = \tilde P = P\tilde P $$
f)
Nechť $\vv x \in \R^n$ pevné. Mějme $P \vv z \in \im P$ Vezměme libovolné $\vv y \in \im P$ a spočítáme $\norm {\vv y - \vv x}^2$ Pak $$ \norm {\vv y - \vv x}^2 = \norm{P \vv x - x + y - P \vv x}^2 = \scal {(P \vv x - \vv x) + (\vv y - P \vv x)} {(P \vv x - \vv x) + (\vv y - P \vv x)} $$
Pro skalární součin platí $$\scal {\vv u} {\vv v} = \scal {\vv v} {\vv u} \ \scal {\vv u + \vv v} {\vv w} = \scal {\vv u} {\vv w} + \scal {\vv v} {\vv w} \ \scal {\vv u} {a\vv v} = a \scal {\vv u} {\vv v}, ; a \in \R $$
Pak dostáváme $$ = \norm{P \vv x - \vv x}^2 + 2 \scal {P \vv x - \vv x} {\vv y - P \vv x} + \norm{\vv y - P \vv x}^2 $$
A zajímá nás hlavně $\scal {P \vv x - \vv x} {\vv y - P \vv x}$, tedy
$$ \scal {P \vv x - \vv x} {\vv y - P \vv x} = (\vv y - P \vv x)^T (P \vv x - \vv x) = \vv y^T (P \vv x - \vv x) - (P \vv x)^T P \vv x - \vv x = $$ $$ = \vv y^T P \vv x - \vv y^T \vv x - \vv x^T \underbrace{P^T P}_ {P} \vv x + \vv x^T P^T \vv x = \vv y^T P \vv x - \vv y^T \vv x $$
Jelikož $\vv y \in \im P$, tak jistě $\exists \vv z \in \R^n$ takové, že $\vv y = P \vv z$. Z toho plyne
$$ \vv y^T P \vv x - \vv y^T \vv x = (P \vv z)^T P \vv x - (P \vv z)^T \vv x = \vv z^T \underbrace{P^T P}_ {P} \vv x - \vv z^T \underbrace{P^T}_ {P} \vv x = 0 $$
Celkem $\norm {\vv y - \vv x}^2$ závisí pouze na $\norm {\vv y - P\vv x}^2$ a $$ \norm{P \vv x - \vv x}^2 + \underbrace{2 \scal {P \vv x - \vv x} {\vv y - P \vv x}}_{0} + \norm{\vv y - P \vv x}^2 \geq \norm{P \vv x - \vv x}^2 $$ a rovnost nastane pouze v případě $P \vv x = \vv y$.
Zadání v R
Vykreslit si grafy hustot a distribučních funkcí pro
- $N(0,1)$ a spočítat $P(X \leq 2)$
- Studentovo $t(df = 5)$ a spočítat $P(X \leq 2)$
- $\chi^2(df = 10)$ a spočítat $P(X \leq 20)$
- Fisherovo $F(5, 10)$ a spočítat $P(X \leq 2)$
a vypočtěte 95% kvantil a zaznačte do grafu
5. cvičení
$$ \xdef\mcal#1{\mathcal{#1}} \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\N{\mathbb N} \xdef\R{\mathbb R} \xdef\Q{\mathbb{Q}} \xdef\Z{\mathbb{Z}} \xdef\D{\mathbb{D}} \xdef\bm#1{\boldsymbol{#1}} \xdef\vv#1{\mathbf{#1}} \xdef\vvp#1{\pmb{#1}} \xdef\floor#1{\lfloor #1 \rfloor} \xdef\ceil#1{\lceil #1 \rceil} \xdef\grad#1{\mathrm{grad} , #1} \xdef\ve{\varepsilon} \xdef\im#1{\mathrm{im}(#1)} \xdef\tr#1{\mathrm{tr}(#1)} \xdef\norm#1{\left\vert \left\vert #1 \right\vert\right\vert} \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\ex#1{\mathrm{E} ,\left( #1\right)} \xdef\exv#1{\mathrm{E}, \vv{#1}} $$
4. cvičení / 2. příklad
a) i b)
Mějme vektor $\vv u \in \R^n$ (takový, že $\norm{\vv u} = 1$), pak matice $$ P = \frac {\vv u \vv u^T} {\norm {\vv u}^2} $$ je ortogonální projekce na $\im {\vv u}$.
Pro ortogonální projekci platí
- $P = P \cdot P$ - idempotence projekce
- $P$ je symetrická (z ortogonality)
Pak $$ P = \frac {\vv u \vv u^T} {\norm {\vv u}^2} $$ a tedy $$ PP = \frac {\vv u \vv u^T} {\norm {\vv u}^2} \frac {\vv u \vv u^T} {\norm {\vv u}^2} $$
Z definice skalárního součiny $\scal {\vv u} {\vv u} = \norm {\vv u}^2$ a proto $$ PP = \frac {\vv u \vv u^T} {\norm{\vv u}^2} = P, $$ což zvláště platí pro $\norm{\vv u} = 1$. Pro nějaké $\vv x \in \R^n$ máme $$ P \vv x = \frac {\vv u \vv u^T \vv x} {\norm {\vv u}^2} = \frac {\vv u \scal {\vv u} {\vv x}} {\norm{\vv u}^2} = \underbrace{\frac {\scal {\vv u} {\vv x}} {\norm{\vv u}^2}}_ {\in \R} \vv u \in \im {\vv u} $$
c)
Mějme ${ \vv u_ 1, \dots, \vv u_ p }$ ortonormální vektory, pak matice $$ P = U U^T, $$ kde $U = (\vv u_ 1 \; \vv u_ 2 \; \dots \; \vv u_ p)$, je ortogonální projekce na $\im U$.
Ukažme $$ P \cdot P = U \underbrace{U^T U}_ {I} U^T = U U^T $$ a $$ P\vv x = U U^T \vv x = U \cdot \begin{pmatrix} \scal {\vv u_ 1} {\vv x} \ \scal {\vv u_ 2} {\vv x} \ \vdots \ \scal {\vv u_ p} {\vv x} \ \end{pmatrix} = \underbrace{\vv u_ 1 \scal {\vv u_ 1} {\vv x}}_ {\in \R} + \dots + \underbrace{\vv u_ p \scal {\vv u_ p} {\vv x}}_ {\in \R} \in \im U, $$ což je lineární kombinace vektorů $\vv u_1, \dots, \vv u_p$ a jistě tedy $P \vv x \in \im U$.
d) i e)
Máme lineárně nezávislé vektory ${\vv a_1, \dots, \vv a_n}$, pak $$ P = A(A^T A)^{-1}A^T $$ je ortogonální projekce.
Jednou možností by bylo použít spektrální rozklad $A = U \Sigma V$, čehož bychom dostali $P = U U^T$, což jsme ukázali v bodě c).
Druhá možnost je $$ PP = A(A^T A)^{-1}\underbrace{A^T A(A^T A)^{-1}}_ {I}A^T = P, $$ což stejně fungovalo i pro pseudoinverzi. Dále $$ A \vv x = \vv y \in \im A, $$ pak $$ P \vv y = (A(A^T A)^{-1}A^T) \vv y = A \underbrace{(A^T A)^{-1}A^T A}_ {I} \vv x = A \vv x = \vv y $$
Zde jsme jen ukázali něco o $\vv y \in \im A$, nikoliv o obecném $\vv x \in \R^p$
5. cvičení / 1. příklad
Nechť $$ \exv X = \begin{pmatrix} \ex X_1 \ \ex X_2 \ \vdots \ \ex X_n \end{pmatrix} $$ a $DX = Var X = Cov(\vv X, \vv X)$ platí $$ Cov(\vv X, \vv X) = \begin{pmatrix} Cov(X_1, X_1) & Cov(X_1, X_2) & \dots & Cov(X_1, X_n) \ Cov(X_2, X_1) & Cov(X_2, X_2) & \dots & Cov(X_2, X_n) \ \vdots & \vdots & \ddots & \vdots \ Cov(X_n, X_1) & Cov(X_n, X_2) & \dots & Cov(X_n, X_n) \end{pmatrix} $$
a)
Ukažme $$ \ex {A \vv X + \vv b} = A\cdot \exv X + \vv b, $$ což je analogické k jednorozměrnému případu.
Pro $i$-tý prvek platí $$ \ex {\sum_{k = 1}^n a_{i,k} X_k + b_i} = \sum_{k = 1}^n \ex {X_k} + b_i, $$ což je, co jsme potřebovali.
b)
Ukažme $$ Var(A\vv X + \vv b) = A \cdot Var \vv X \cdot A^T $$ což je opět analogie k $D(a X + b) = a^2 D X$.
Využijeme vlastnost kovariance. Tedy pro $(i,j)$-tý prvek matice $A \vv X + \vv b$ platí $$ Cov \left( \sum_{k = 1}^n a_{i,k} X_k + b_i, \sum_{k = 1}^n a_{j,k} X_k + b_j \right) = \sum_{k = 1}^n \sum_{l = 1}^n a_{i,k} a_{j,l} Cov (X_k, X_l) = $$ $$ = \sum_{l = 1}^n \left( \sum_{k = 1}^n a_{i,k} Cov(X_k, X_l) \right) a_{j,l} $$
c)
Máme ukázat $$ \ex {\vv X^T \vv X} = \exv X^T \exv X + tr(Var(\vv X)), $$ což je ekvivalentní s $$ \ex{X_1^2 + X_2^2 + \dots + X_n^2} = \ex{X_1}^2 + \dots + \ex{X_n}^2 + DX_1 + \dots + DX_n $$
Obecně platí $$ Var(\vv X) = \ex{\vv X \vv X^T} - \exv X \cdot \exv X^T $$ a tedy $$ \ex {\vv X^T \vv X} = \ex {tr(\vv X^T \vv X)} = $$ pak dle vlastnosti stopy matice $$ = \ex {tr(\vv X \vv X^T)} = tr(\ex{\vv X \vv X^T}) = tr(Var(\vv X) + \exv X \cdot \exv X^T) = $$ a opět dle vlastnosti stopy matice $$ = tr(Var(\vv X)) + tr(\exv X \cdot \exv X^T) = \exv X^T \cdot \exv X + tr(Var(\vv X)) $$
7. cvičení
$$ \xdef\mcal#1{\mathcal{#1}} \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\N{\mathbb N} \xdef\R{\mathbb R} \xdef\Q{\mathbb{Q}} \xdef\Z{\mathbb{Z}} \xdef\D{\mathbb{D}} \xdef\bm#1{\boldsymbol{#1}} \xdef\vv#1{\mathbf{#1}} \xdef\vvp#1{\pmb{#1}} \xdef\floor#1{\lfloor #1 \rfloor} \xdef\ceil#1{\lceil #1 \rceil} \xdef\grad#1{\mathrm{grad} , #1} \xdef\ve{\varepsilon} \xdef\im#1{\mathrm{im}(#1)} \xdef\tr#1{\mathrm{tr}(#1)} \xdef\norm#1{\left\vert \left\vert #1 \right\vert\right\vert} \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\ex#1{\mathrm{E} ,\left( #1\right)} \xdef\exv#1{\mathrm{E}, \vv{#1}} $$
Nechť $$ \vv Y $$ jsou data, $$ \hat {\vv Y} = \vv X \hat {\vvp \beta}, \qquad E \hat{\vv Y} = E \vv Y $$ je odhad $\vv Y$ a $$ \vv e $$ je odhad $\vvp \ve$.
A máme celkovou sumu čtverců $$ TSS = \sum_{i = 1}^n (Y_i - \overline Y_i)^2 $$ také vysvětlovanou sumu čtverců $$ ESS = \sum_{i = 1}^n(\hat Y_i - \overline Y_i)^2 $$ a neposlední řadě reziduální sumu čtverců $$ RSS = \sum_{i = 1}^n (Y_i- \hat Y_i)^2 $$
A platí $$ TSS = RSS + ESS $$
a nechť $R^2$ je koeficient determinace $$ R^2 = \frac {ESS} {TSS} \in (0, 1] $$ a adjustovaný koeficient determinace $$ R^2_{adj} = 1 - \frac {\cfrac {RSS} {n-p}} {\cfrac {TSS} {n-1}} $$
Dále
$$
\hat \sigma^2 = \frac {RSS} {n - p}
$$
a
$$
var(\hat{\vvp \beta}) = \hat \sigma^2 (\vv X^T \vv X)^{-1}
$$
Přičemž $var(\hat{\vvp \beta})$ dostaneme pomocí vcov(<model>)
9. cvičení
a) IS pro $\beta_i$: $$ T_i = \frac {\hat{\beta_i}} {\sqrt{\hat{\sigma} (\pmb X^T \pmb X)^{-1}_{i,i}}} \sim t(n-p) $$
Pak $$ P\left(T_ i \in \left[t_{\frac \alpha 2}(n-p), t_{1 - \frac \alpha 2}(n-p)\right]\right) = 1 - \alpha $$ $$ t_{\frac \alpha 2}(n-p) \leq T_ i \leq t_ {1 - \frac \alpha 2}(n-p) $$ $$ t_{\frac \alpha 2}(n-p) \leq \frac {\beta_i - \hat{\beta_ i}} {\sqrt{\hat{\sigma}^2 (\pmb X^T \pmb X)^{-1}_ {i,i}}} \leq t_{1 - \frac \alpha 2}(n-p) $$ Z čehož dostaneme $$ \beta_ i \in \left(\hat{\beta_ i} \pm t_{1-\frac \alpha 2}(n-p) \sqrt{\hat{\sigma}^2 (\pmb X^T \pmb X)^{-1}_ {i,i}}\right) $$
b) $$ T = \frac {\pmb a^T \pmb \beta^T} {\sqrt{\hat{\sigma}^2 \pmb a^T (\pmb X^T \pmb X)^{-1} \pmb a}} \sim t(n-p) $$
$$ \left(\pmb a^T \pmb \beta \pm t_{1-\frac \alpha 2}(n-p) \sqrt{\hat{\sigma}^2 \pmb a^T (\pmb X^T \pmb X)^{-1} \pmb a}\right) $$
A regresní přímka pro dívky bude mít tvar $$ y = \hat \beta_0 + \hat \beta_1 x $$ Pro chlapce: $$ y = \hat \beta_0 + \hat \beta_2 + (\hat \beta_1 + \hat \beta_3) x $$ IS pro $\beta_1 + \beta_3$, tedy $\pmb a = (0, 1, 0, 1)$
d) Při počítání predikčního intervalu zohledňujeme chybu u "nového pozorování". Tedy odhad rozptylu je $$ \hat{\sigma}^2 \pmb x^T (\pmb X^T \pmb X)^{-1} \pmb x + \hat \sigma^2 \implies T = \frac {\pmb x^T \pmb \beta^T} {\sqrt{\hat{\sigma}^2(1 + \pmb x^T (\pmb X^T \pmb X)^{-1} \pmb x)}} \sim t(n-p) $$
# Confidence interval
predict(..., interval = "confidence")
# Or
predict(..., interval = "prediction")
10. cvičení
$$ \xdef\mcal#1{\mathcal{#1}} \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\N{\mathbb N} \xdef\R{\mathbb R} \xdef\Q{\mathbb{Q}} \xdef\Z{\mathbb{Z}} \xdef\D{\mathbb{D}} \xdef\bm#1{\boldsymbol{#1}} \xdef\vv#1{\mathbf{#1}} \xdef\vvp#1{\pmb{#1}} \xdef\floor#1{\lfloor #1 \rfloor} \xdef\ceil#1{\lceil #1 \rceil} \xdef\grad#1{\mathrm{grad} , #1} \xdef\ve{\varepsilon} \xdef\im#1{\mathrm{im}(#1)} \xdef\tr#1{\mathrm{tr}(#1)} \xdef\norm#1{\left\vert \left\vert #1 \right\vert\right\vert} \xdef\scal#1#2{\langle #1, #2 \rangle} \xdef\ex#1{\mathrm{E} ,\left( #1\right)} \xdef\exv#1{\mathrm{E}, \vv{#1}} \xdef\mtrx#1{\begin{pmatrix}#1\end{pmatrix}} $$
Scheffeho věta $$ P\left([\vv b^T (A\hat\beta - A \beta)]^2 \leq m F_{1 - \alpha}(m, n - p) \hat \sigma^2 \vv b^T A (\vv X^T \vv X)^{-1} A^T \vv b\right) = 1 - \alpha $$ $\forall b \in \R^m$, je-li matice $A$ typu $m \times p$ plné hodnosti.
Příklad $$ Y_i = \beta_0 + \beta_1 \cdot \text{Height}_I + \beta_2 \cdot \text{Sex}_i + \beta_3 \cdot (\text{Height} + \text{Sex})_i + \ve_i, \quad \ve \sim N(0, \sigma^2) $$ a chceme zkonstruovat 95% PS pro chlapce a dívky
1) Napíšeme tvar reg. křivky
- d: $y = \hat \beta_0 + \hat\beta_1 x$
- ch: $y = \hat\beta_0 + \hat\beta_2 + (\hat \beta_1 + \hat \beta_3)x$
2) Zvolíme vhodný tvar $\vv b$ a $A$:
-
d: $\vv b = \mtrx{1 \ x} \in \R^2$, pak $$ \mtrx{1 & x} \overbrace{\mtrx{1 & 0 & 0 & 0 \ 0 & 1 & 0 & 0}}^A \mtrx{\hat \beta_1 \ \hat \beta_2 \ \hat \beta_3 \ \hat \beta_4} $$
-
ch: $\vv b = \mtrx{1 \ x}$, pak $$ \mtrx{1 & x} \overbrace{\mtrx{1 & 0 & 1 & 0 \ 0 & 1 & 0 & 1}}^A \mtrx{\hat \beta_1 \ \hat \beta_2 \ \hat \beta_3 \ \hat \beta_4} $$
Nejprve počítejme pro dívky, Označme $$ \vv b^T A = \vv x^T = (1, x, 0, 0) $$ 3) Odvodíme tvar pásu spolehlivosti (PS) $$ P\left([\vv x^T \hat \beta - \underbrace{\vv x^T \beta}_ {y = \beta_0 + \beta_1 x}]^2 \leq 2 F_ {1 - \alpha}(2, n - 4) \sigma^2 \vv x^T (\vv X^T \vv X)^{-1} \vv x \right) = 1 - \alpha $$ kde $y$ je náhodná proměnná. Upravujme
$$ P\left(|\vv x^T \hat \beta - y| \leq \sqrt{2 F_{1 - \alpha}(2, n - 4) \sigma^2 \vv x^T (\vv X^T \vv X)^{-1} \vv x} \right) = 1 - \alpha $$
- pro $\vv x^T \hat \beta - y > 0$ dostáváme dolní hranici $$ P\left(y \geq \vv x^T \hat \beta - \sqrt{2 F_{1 - \alpha}(2, n - 4) \sigma^2 \vv x^T (\vv X^T \vv X)^{-1} \vv x} \right) = 1 - \alpha $$
- nebo pro $\vv x^T \hat \beta - y < 0$ dostáváme horní hranici $$ P\left(y \leq \vv x^T \hat \beta + \sqrt{2 F_{1 - \alpha}(2, n - 4) \sigma^2 \vv x^T (\vv X^T \vv X)^{-1} \vv x} \right) = 1 - \alpha $$